
印象笔记同步分享:《程序员面试宝典》学习记录6
考点1:面向对象三大特性
1)封装性:封装,也就是把客观事物封装成抽象的类,并且类可以把自己的数据和方法只让可信的类或者对象操作,对不可信的进行信息隐藏。(开闭原则)
在C++中类中成员的属性有:public, protected, private,这三个属性的访问权限依次降低。
2)继承性:继承是指这样一种能力:它可以使用现有类的所有功能,并在无需重新编写原来的类的情况下对这些功能进行扩展。(里氏代换)interface
3)多态性:多态性(polymorphisn)是允许你将父对象设置成为和一个或更多的他的子对象相等的技术,赋值之后,父对象就可以根据当前赋值给它的子对象的特性以不同的方式运作。简单的说,就是一句话:允许将子类类型的指针赋值给父类类型的指针。实现多态,有二种方式,覆盖,重载。
覆盖,是指子类重新定义父类的虚函数的做法。
重载,是指允许存在多个同名函数,而这些函数的参数表不同(或许参数个数不同,或许参数类型不同,或许两者都不同)。virtual
考点2:C++中空类默认产生哪些类成员函数?
对于一个空类,编译器默认产生4个成员函数:
1)默认构造函数
2)析构函数
3)拷贝构造函数
4)赋值函数
考点1:结构是否可以有构造函数、析构函数及成员函数?如果可以,那么结构和类还有什么区别吗?
区别是class中变量默认是private,struct中的变量默认是public。struct可以有构造函数、析构函数,之间也可以继承甚至是多重继承,等等。C++中的struct其实和class意义一样,唯一不同就是struct里面默认的访问控制是public,class中默认访问控制是private。C++中存在struct关键字的唯一意义就是为了让C程序员有个归属感,是为了让C++编译器兼容以前用C开发的项目。
考点2:准确理解结构struct
struct Test
{
Test(int){}
Test(){}
void fun(){}
};
int main()
{
Test a(1);
a.fun();
Test b(); //这里和上面不一样这个相当于声明一个函数,函数名为b,返回值为Test,传入参数为空,作者的目的应该是声明一个类型Test,变量为b的变量,所以改为 Test b 下一句才不会错误
b.fun();//所以这个会发生错误
return 0;
}
构造函数:Test a(1)表示存在默认拷贝构造函数 Test b 表示存在默认无参数的构造函数
考点1:成员变量的初始化
class test
{
private:
int a; 普通成员
const int b; 常量成员
static int c; 静态成员
static const int d; 静态常量成员
int &e; 引用类型成员
}
记住下面几个原则:
1)常量成员(注意没有静态常量成员)和引用类型成员只能用成员初始化列表对成员变量初始化
2)静态成员和静态常量成员由于是类共有的,不是属于某一个对象的,因此不能在构造函数中初始化3)静态成员(注意没有静态常量成员)必须在类外初始化
4)引用变量必须初始化才能使用
5)只有静态常量成员才能在类中直接赋值初始化
6)初始化列表初始化变量顺序根据成员变量的声明顺序来执行,而和在程序中赋值先后顺序无关
class test
{
int a=1; 错误,对象还没有构造,尚未分配内存空间
int a;
const b;
static int c = 1; 错误,不可以再声明时初始化
static int c;
const static int d = 1; 唯有静态常量成员才能在类中直接赋值初始化
int &e; 引用类型必须用成员初始化列表
public:
test(int _e):b(1),e(_e) 引用初始化必须为左值
test(int _e):b(1),e(_e){}
};
int test::c=1;
const int test::d=1;
考点2:C++成员变量初始化顺序
class A
{
private:
int n1;
int n2;
public:
A():n2(0),n1(n2+2){}
void Print(){
cout << "n1:" << n1 << ", n2: " << n2 <<endl;
}
};
int main()
{
A a;
a.Print();
return 1;
}
输出结果为:n1:1874928131 n2:0
成员变量在使用初始化列表初始化时,与构造函数中初始化成员列表的顺序无关,只与定义成员变量的顺序有关。因为成员变量的初始化次序是根据变量在内存中次序有关,而内存中的排列顺序早在编译期就根据变量的定义次序决定了。
修改为:
A()
{
n2 = 0;
n1 = n2 +2;
}
这样输出就是n1:2 n2:0
考点3:区分于常量成员和静态常量成员
下面这个类声明正确吗?为什么?
class A
{
const int Size = 0;
};
解析:这道程序题存在着成员变量问题。常量必须在构造函数的初始化列表里初始化或者将其设置成static。
正确的程序如下:
class A
{
A()
{
const int Size = 1;
}
};
或者:
class A
{
static const int Size = 1;
};
考点1:构造函数与析构函数有什么特点?
构造函数与析构函数区别:
1)构造函数和析构函数是在类体中说明的两种特殊的成员函数。
构造函数的功能是在创建对象时,使用给定的值来将对象初始化。
析构函数的功能是用来释放一个对象的。在对象删除前,用它来做一些清理工作,它与构造函数的功能正好相反。
2)构造函数可以有一个参数也可以有多个参数,构造函数可以重载,即定义多个参数个数不同的函数;但是析构函数不指定数据类型,也没有参数,且一个类中只能定义一个析构函数,不能重载。
3)程序不能直接调用构造函数,在创建对象时系统自动调用构造函数;析构函数可以被调用,也可以由系统调用。析构函数可以内联
析构函数会被自动调用的两种情况:①当这个函数结束时,对象的析构函数被自动调用;②当一个对象使用new运算符被动创建时候,在使用delete运算符释放它,delete将会自动调用析构函数。
考点2:为什么虚拟的析构函数是必要的?
保证了在任何情况下,都不会出现由于析构函数未被调用而导致的内存泄露。
考点3:析构函数可以为 virtual 型,构造函数则不能,为什么?
虚函数采用一种虚调用的办法。虚调用是一种可以在只有部分信息的情况下工作的机制,特别允许我们调用一个只知道接口而不知道其准确对象类型的函数。但是如果要创建一个对象,你势必要知道对象的准确类型,因此构造函数不能为 virtual。
考点4:如果虚函数是非常有效的,我们是否可以把每个函数都声明为虚函数?
不行,这是因为虚函数是有代价的:由于每个虚函数的对象都必须维护一个 v 表,因此在使用虚函数的时候会产生一个系统开销。如果仅是一个很小的类,且不行派生其他类,那么根本没必要使用虚函数。
考点5:显式调用析构函数
#include <iostream>using namespace std;
class MyClass
{
public:
MyClass()
{
cout << "Constructors" << endl;
}
~MyClass()
{
cout << "Destructors" << endl;
}
};
int main()
{
MyClass* pMyClass = new MyClass;
pMyClass->~MyClass();
delete pMyClass;
return 0;
}
运行结果:
结果:
Constructors
Destructors //这个是显示调用的析构函数
Destructors //这个是delete调用的析构函数
总结:
new的时候,其实做了三件事,一是:调用::operator new分配所需内存。二是:调用构造函数。三是:返回指向新分配并构造的对象的指针。
delete的时候,做了两件事,一是:调用析构函数,二是:调用::operator delete释放内存。
考点1:编写类string的构造函数、析构函数、赋值函数
已知类的原型为:
class String
{
public:
String(const char *str = NULL); 普通构造函数
String(const String &other); 拷贝构造函数
~String(void); 析构函数
String & operate = (const String &other); 赋值函数
private:
char *m_data; 用于保存字符串
};
析构函数:
String::~String(void)
{
delete[] m_data;
}
构造函数:
String::String(const char *str)
{
if(str==NULL)
{
m_data = new char[1];//若能加NULL,判断更好
*m_data = '�';
}
else
{
int length = strlen(str);
m_data = new char[length+1];
strcpy(m_data,str);
}
}
拷贝构造函数:
String::String(const String &other)
{
int length = strlen(other.m_data);
m_data = new char[length+1];
strcpy(m_data,other.m_data);
}
赋值函数:
String & String::operate = (const String &other)
{
if(this == &other) //检查自复制
{
return *this;
}
delete [] m_data; //释放原有的资源
int length = strlen(other.m_data); //分配新内存资源,并复制内容
m_data = new char[length+1];
strcpy(m_data,other.m_data);
return *this;//返回本对象的引用
}
考点2:区分默认构造函数、默认拷贝构造函数、默认析构函数、默认赋值函数
A() 默认构造函数
A(const A&) 默认拷贝构造函数
~A 默认析构函数
A& operator = (const A &) 默认赋值函数
CTemp a(b); 复制构造函数,C++风格的初始化
CTemp a = b; 复制构造函数,不过这种风格只是为了与C兼容
CTemp a;
a = b; 赋值函数
区分:不同之处在于:赋值运算符处理两个已有对象,即赋值前B应该是存在的;复制构造函数是生成一个全新的对象,即调用复制构造函数之前B不存在;拷贝构造函数是构造函数,不返回值,而赋值函数需要返回一个对象自身的引用,以便赋值之后的操作。
考点3:拷贝构造函数深入理解
1)拷贝构造函数里能调用private成员变量吗?
拷贝构造函数其时就是一个特殊的构造函数,操作的还是自己类的成员变量,所以不受private的限制。
2)以下函数哪个是拷贝构造函数,为什么?
X::X(const X&); 拷贝构造函数
X::X(X);
X::X(X&, int a=1); 拷贝构造函数
X::X(X&, int a=1, int b=2); 拷贝构造函数
对于一个类X, 如果一个构造函数的第一个参数是下列之一:
a) X& b) const X& c) volatile X& d) const volatile X&
且没有其他参数或其他参数都有默认值,那么这个函数是拷贝构造函数.
3)一个类中存在多于一个的拷贝构造函数吗?
类中可以存在超过一个拷贝构造函数。
class X
{
public:
X(const X&); // const 的拷贝构造
X(X&); // 非const的拷贝构造
};
4)如何防止默认拷贝发生?
声明一个私有拷贝构造函数。甚至不必去定义这个拷贝构造函数,这样因为拷贝构造函数是私有的,如果用户试图按值传递或函数返回该类对象,将得到一个编译错误,从而可以避免按值传递或返回对象。
5)拷贝构造函数一定要使用引用传递呢,我上网查找了许多资料,大家的意思基本上都是说如果用值传递的话可能会产生死循环。
6)理解默认拷贝构造函数
请看下面一段程序:
#include<iostream>using namespace std;
class B
{
private:
int data;
public:
B()
{
cout<<"defualt constructor"<<endl;
}
~B()
{
cout<<"destructed "<<endl;
}
B( int i) : data(i)
{
cout<<"constructed by parameter"<<data<<endl;
}
};
B Play( B b )
{
return b;
}
int main ()
{
B temp = Play(5);
return 0;
}
1)该程序输出结果是什么?为什么会有这样的输出?
2)B(int i):data(i),这种用法的专业术语叫什么?
3)Play(5),形参类型是类,而5是个常量,这样写合法吗?为什么?
(1)输出结果如下:
constructed by parameter 在Play(5)处,5通过隐含的类型转换调用了B::B( int i )
destructed Play(5) 返回时,参数的析构函数被调用
destructed temp的析构函数被调用;temp的构造函数调用的是编译器生存的拷贝构造函数,这个需要特别注意
2)待参数的构造函数,冒号后面的是成员变量初始化列表(member initialization list)
3)合法。单个参数的构造函数如果不添加explicit关键字,会定义一个隐含的类型转换;添加explicit关键字会消除这种隐含转换。
考点4:如何理解浅拷贝和深拷贝?
浅拷贝指的是在对象复制时,只对对象中的数据成员进行简单的赋值,默认拷贝构造函数执行的也是浅拷贝。大多情况下“浅拷贝”已经能很好地工作了,但是一旦对象存在了动态成员,那么浅拷贝就会出问题了。
class Rect
{
public:
Rect() // 构造函数,p指向堆中分配的一空间
{
p = new int(100);
}
~Rect() // 析构函数,释放动态分配的空间
{
if(p != NULL)
{
delete p;
}
}
private:
int width;
int height;
int *p; // 一指针成员
};
int main()
{
Rect rect1;
Rect rect2(rect1); // 复制对象
return 0;
}
这个代码运行会出现这样的错误。
在运行定义rect1对象后,由于在构造函数中有一个动态分配的语句,因此执行后的内存情况大致如下:
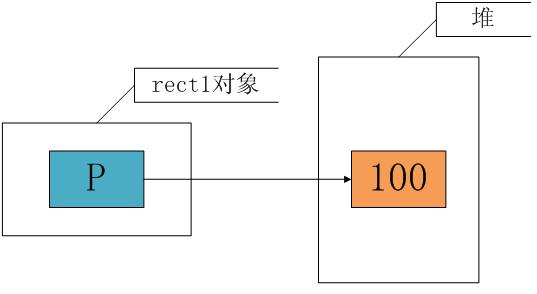
在使用rect1复制rect2时,由于执行的是浅拷贝,只是将成员的值进行赋值,这时 rect1.p = rect2.p,也即这两个指针指向了堆里的同一个空间,如下图所示:
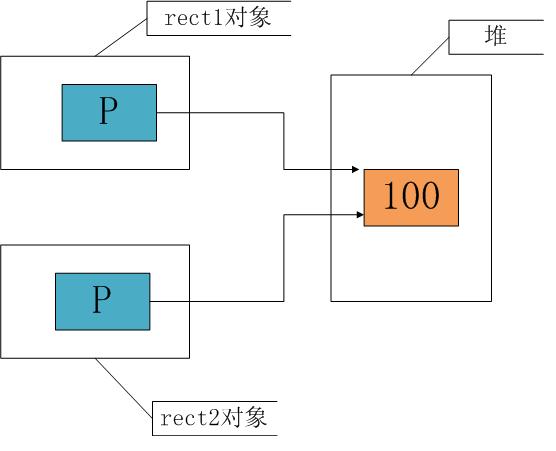
当然,这不是我们所期望的结果,在销毁对象时,两个对象的析构函数将对同一个内存空间释放两次,这就是错误出现的原因。我们需要的不是两个p有相同的值,而是两个p指向的空间有相同的值,解决办法就是使用“深拷贝”。
深拷贝:在“深拷贝”的情况下,对于对象中动态成员,就不能仅仅简单地赋值了,而应该重新动态分配空间
class Rect
{
public:
Rect() // 构造函数,p指向堆中分配的一空间
{
p = new int(100);
}
Rect(const Rect& r)
{
width = r.width;
height = r.height;
p = new int; // 为新对象重新动态分配空间
*p = *(r.p);
}
~Rect() // 析构函数,释放动态分配的空间
{
if(p != NULL)
{
delete p;
}
}
private:
int width;
int height;
int *p; // 一指针成员
};
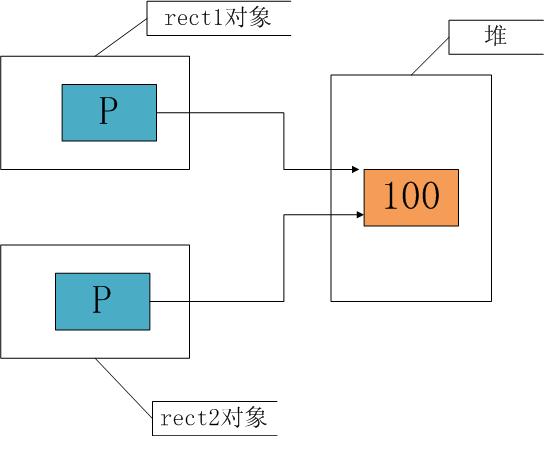
此时rect1的p和rect2的p各自指向一段内存空间,但它们指向的空间具有相同的内容,这就是所谓的“深拷贝”。
考点1:理解多态性
多态性可以简单地概括为“一个接口,多种方法”,程序在运行时才决定调用的函数,它是面向对象编程领域的核心概念。多态(polymorphisn),字面意思多种形状。
多态的作用是什么呢?
封装可以使得代码模块化,继承可以扩展已存在的代码,他们的目的都是为了代码重用。而多态的目的则是为了接口重用。也就是说,不论传递过来的究竟是那个类的对象,函数都能够通过同一个接口调用到适应各自对象的实现方法。
考点2:覆盖(override)和重载(overload)区别?
C++多态性是通过虚函数来实现的,虚函数允许子类重新定义成员函数,而子类重新定义父类的做法称为覆盖(override),或者称为重写。(这里我觉得要补充,重写的话可以有两种,直接重写成员函数和重写虚函数,只有重写了虚函数的才能算作是体现了C++多态性)而重载则是允许有多个同名的函数,而这些函数的参数列表不同,允许参数个数不同,参数类型不同,或者两者都不同。编译器会根据这些函数的不同列表,将同名的函数的名称做修饰,从而生成一些不同名称的预处理函数,来实现同名函数调用时的重载问题。但这并没有体现多态性。
考点3:多态与非多态的区别?
多态与非多态的实质区别就是函数地址是早绑定还是晚绑定。如果函数的调用,在编译器编译期间就可以确定函数的调用地址,并生产代码,是静态的,就是说地址是早绑定的。而如果函数调用的地址不能在编译器期间确定,需要在运行时才确定,这就属于晚绑定。
考点4:多态的用法
#include<iostream>using namespace std;
class A
{
public:
void foo()
{
printf("1
");
}
virtual void fun()
{
printf("2
");
}
};
class B : public A
{
public:
void foo()
{
printf("3
");
}
void fun()
{
printf("4
");
}
};
int main(void)
{
A a;
B b;
A *p = &a;
p->foo();
p->fun();
p = &b;
p->foo();
p->fun();
return 0;
}
第一个p->foo()和p->fuu()都很好理解,本身是基类指针,指向的又是基类对象,调用的都是基类本身的函数,因此输出结果就是1、2。
第二个输出结果就是1、4。p->foo()和p->fuu()则是基类指针指向子类对象,正式体现多态的用法,p->foo()由于指针是个基类指针,指向是一个固定偏移量的函数,因此此时指向的就只能是基类的foo()函数的代码了,因此输出的结果还是1。而p->fun()指针是基类指针,指向的fun是一个虚函数,由于每个虚函数都有一个虚函数列表,此时p调用fun()并不是直接调用函数,而是通过虚函数列表找到相应的函数的地址,因此根据指向的对象不同,函数地址也将不同,这里将找到对应的子类的fun()函数的地址,因此输出的结果也会是子类的结果4。
笔试的题目中还有一个另类测试方法。即
B *ptr = (B *)&a; ptr->foo(); ptr->fun();
问这两调用的输出结果。这是一个用子类的指针去指向一个强制转换为子类地址的基类对象。结果,这两句调用的输出结果是3,2。
并不是很理解这种用法,从原理上来解释,由于B是子类指针,虽然被赋予了基类对象地址,但是ptr->foo()在调用的时候,由于地址偏移量固定,偏移量是子类对象的偏移量,于是即使在指向了一个基类对象的情况下,还是调用到了子类的函数,虽然可能从始到终都没有子类对象的实例化出现。而ptr->fun()的调用,可能还是因为C++多态性的原因,由于指向的是一个基类对象,通过虚函数列表的引用,找到了基类中fun()函数的地址,因此调用了基类的函数。由此可见多态性的强大,可以适应各种变化,不论指针是基类的还是子类的,都能找到正确的实现方法。
考点5:隐藏规则
这里“隐藏”是指派生类的函数屏蔽了与其同名的基类函数,规则如下:
(1)如果派生类的函数与基类的函数同名,但是参数不同。此时,不论有无virtual
关键字,基类的函数将被隐藏(注意别与重载混淆)。
(2)如果派生类的函数与基类的函数同名,并且参数也相同,但是基类函数没有virtual
关键字。此时,基类的函数被隐藏(注意别与覆盖混淆)。
小结:1、有virtual才可能发生多态现象
2、不发生多态(无virtual)调用就按原类型调用
#include<iostream>using namespace std;
class Base
{
public:
virtual void f(float x)
{
cout<<"Base::f(float)"<< x <<endl;
}
void g(float x)
{
cout<<"Base::g(float)"<< x <<endl;
}
void h(float x)
{
cout<<"Base::h(float)"<< x <<endl;
}
};
class Derived : public Base
{
public:
virtual void f(float x)
{
cout<<"Derived::f(float)"<< x
生活不易,码农辛苦
如果您觉得本网站对您的学习有所帮助,可以手机扫描二维码进行捐赠

程序员人生,我编程,我富裕,记住wfuyu网,php教程,php学习,php手册,CMS模版制作
声明:本站大部分内容是作者原创,少部分收集于互联网供大家一起学习,原版权很多不明,如有侵权请联系本站,谢谢!
粤ICP备14040726号-1 2015-2020 程序员人生 版权所有


