
在业务开发中,我们常把数据持久化到数据库中。如果需要读取这些数据,除直接从数据库中读取外,为了减轻数据库的访问压力和提高访问速度,我们更多地引入缓存来对数据进行存取。读取数据的进程1般为:
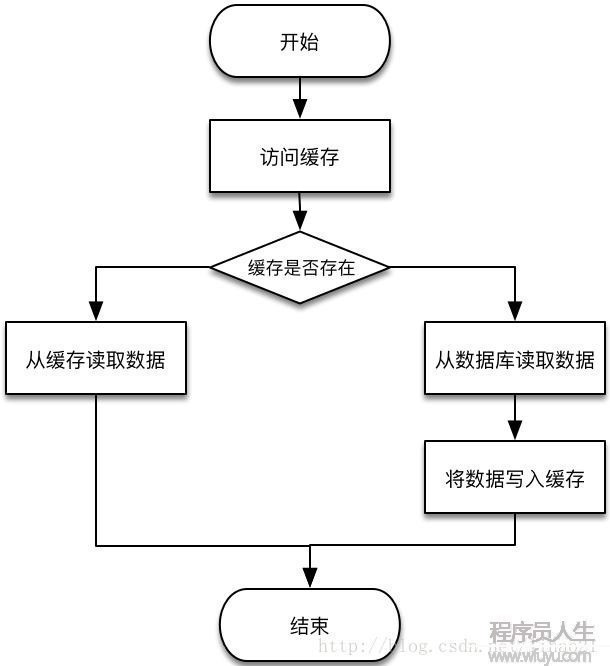
图1:加入缓存的数据读取进程
对散布式缓存,不同机器上存储不同对象的数据。为了实现这些缓存机器的负载均衡,可使用式子1来定位对象缓存的存储机器:
m = hash(o) mod n ——式子1
其中,o为对象的名称,n为机器的数量,m为机器的编号,hash为1hash函数。图2中的负载均衡器(load balancer)正是使用式子1来将客户端对不同对象的要求分派到不同的机器上履行,例如,对对象o,经过式子1的计算,得到m的值为3,那末所有对对象o的读取和存储的要求都被发往机器3履行。
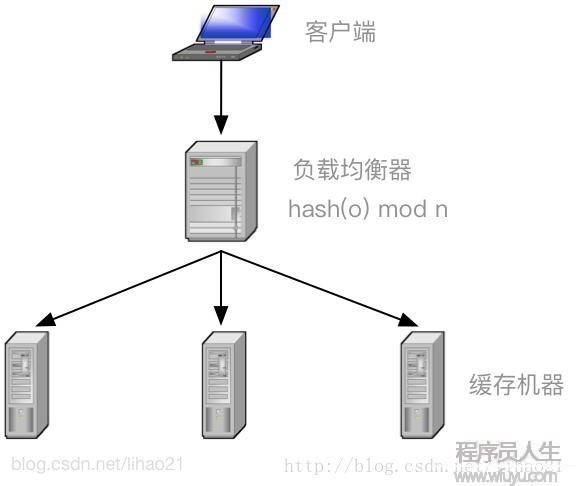
图2:如何利用Hash取模实现负载均衡
式子1在大部份时候都可以工作得很好,但是,当机器需要扩容或机器出现宕机的情况下,事情就比较辣手了。
当机器扩容,需要增加1台缓存机器时,负载均衡器使用的式子变成:
m = hash(o) mod (n + 1) ——式子2
当机器宕机,机器数量减少1台时,负载均衡器使用的式子变成:
m = hash(o) mod (n - 1) ——式子3
我们以机器扩容的情况为例,说明简单的取模方法会致使甚么问题。假定机器由3台变成4台,对象o1由式子1计算得到的m值为2,由式子2计算得到的m值却可能为0,1,2,3(1个 3t + 2的整数对4取模,其值可能为0,1,2,3,读者可以自行验证),大约有75%(3/4)的可能性出现缓存访问不命中的现象。随着机器集群范围的扩大,这个比例线性上升。当99台机器再加入1台机器时,不命中的几率是99%(99/100)。这样的结果明显是不能接受的,由于这会致使数据库访问的压力陡增,严重情况,还可能致使数据库宕机。
1致性hash算法正是为了解决此类问题的方法,它可以保证当机器增加或减少时,对缓存访问命中的几率影响减至很小。下面我们来详细说1下1致性hash算法的具体进程。
1致性Hash环
1致性hash算法通过1个叫作1致性hash环的数据结构实现。这个环的出发点是0,终点是2^32 - 1,并且出发点与终点连接,环的中间的整数按逆时针散布,故这个环的整数散布范围是[0, 2^32⑴],以下图3所示:
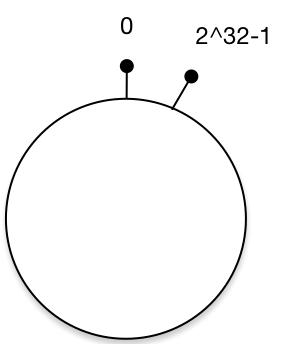
图3:1致性Hash环
将对象放置到Hash环
假定现在我们有4个对象,分别为o1,o2,o3,o4,使用hash函数计算这4个对象的hash值(范围为0 ~ 2^32⑴):
hash(o1) = m1
hash(o2) = m2
hash(o3) = m3
hash(o4) = m4
把m1,m2,m3,m4这4个值放置到hash环上,得到以下图4:
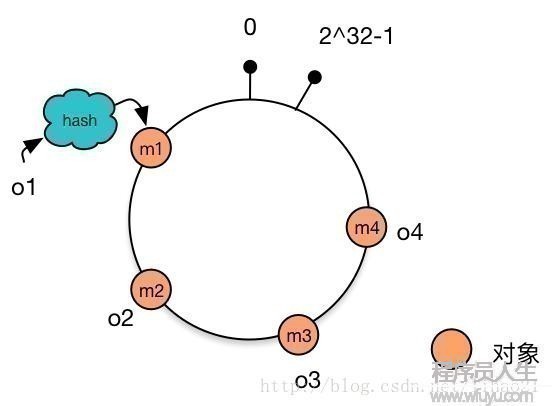
图4:放置了对象的1致性Hash环
将机器放置到Hash环
使用一样的hash函数,我们将机器也放置到hash环上。假定我们有3台缓存机器,分别为 c1,c2,c3,使用hash函数计算这3台机器的hash值:
hash(c1) = t1
hash(c2) = t2
hash(c3) = t3
把t1,t2,t3 这3个值放置到hash环上,得到以下图5:
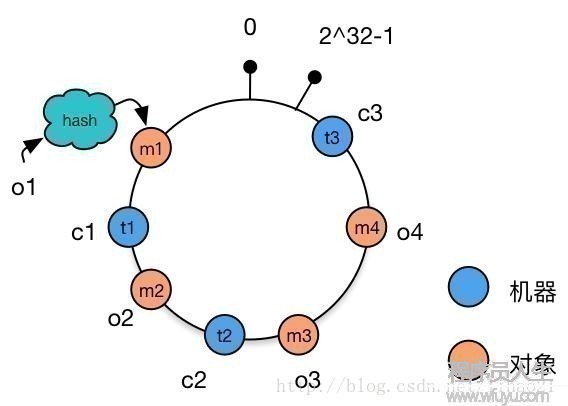
图5:放置了机器的1致性Hash环
为对象选择机器
将对象和机器都放置到同1个hash环后,在hash环上顺时针查找距离这个对象的hash值最近的机器,即是这个对象所属的机器。
例如,对对象o2,顺序针找到最近的机器是c1,故机器c1会缓存对象o2。而机器c2则缓存o3,o4,机器c3则缓存对象o1。
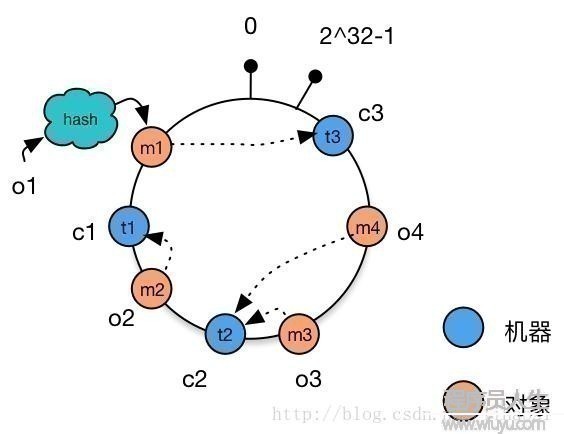
图6:在1致性Hash环上为对象选择机器
处理机器增减的情况
对线上的业务,增加或减少1台机器的部署是常有的事情。
例如,增加机器c4的部署并将机器c4加入到hash环的机器c3与c2之间。这时候,只有机器c3与c4之间的对象需要重新分配新的机器。对我们的例子,只有对象o4被重新分配到了c4,其他对象仍在原有机器上。如图7所示:
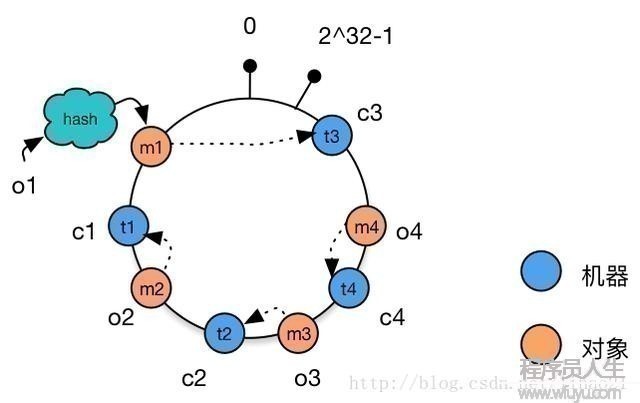
图7:增加机器后的1致性Hash环的结构
如上文前面所述,使用简单的求模方法,当新添加机器后会致使大部份缓存失效的情况,使用1致性hash算法后这类情况则会得到大大的改良。前面提到3台机器变成4台机器后,缓存命中率只有25%(不命中率75%)。而使用1致性hash算法,理想情况下缓存命中率则有75%,而且,随着机器范围的增加,命中率会进1步提高,99台机器增加1台后,命中率到达99%,这大大减轻了增加缓存机器带来的数据库访问的压力。
再例如,将机器c1下线(固然,也有多是机器c1宕机),这时候,只有原有被分配到机器c1对象需要被重新分配到新的机器。对我们的例子,只有对象o2被重新分配到机器c3,其他对象仍在原有机器上。如图8所示:
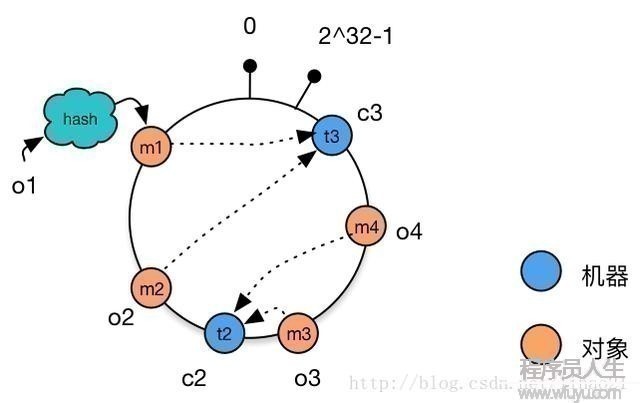
图8:减少机器后的1致性Hash环的结构
虚拟节点
上面提到的进程基本上就是1致性hash的基本原理了,不过还有1个小小的问题。新加入的机器c4只分担了机器c2的负载,机器c1与c3的负载并没有由于机器c4的加入而减少负载压力。如果4台机器的性能是1样的,那末这类结果其实不是我们想要的。
为此,我们引入虚拟节点来解决负载不均衡的问题。
将每台物理机器虚拟为1组虚拟机器,将虚拟机器放置到hash环上,如果需要肯定对象的机器,先肯定对象的虚拟机器,再由虚拟机器肯定物理机器。
说得有点复杂,其实进程也很简单。
还是使用上面的例子,假设开始时存在缓存机器c1,c2,c3,对每一个缓存机器,都有3个虚拟节点对应,其1致性hash环结构如图9所示:
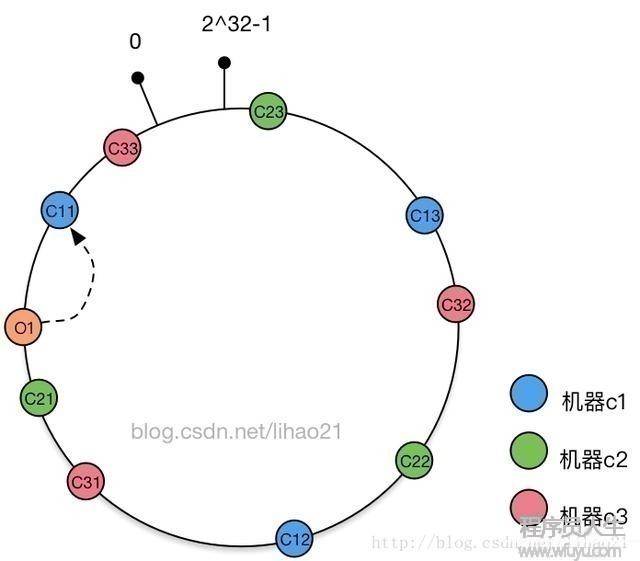
图9:机器c1,c2,c3的1致性Hash环结构
假定对对象o1,其对应的虚拟节点为c11,而虚拟节点c11对象缓存机器c1,故对象o1被分配到机器c1中。
新加入缓存机器c4,其对应的虚拟节点为c41,c42,c43,将这3个虚拟节点添加到hash环中,得到的hash环结构如图10所示:
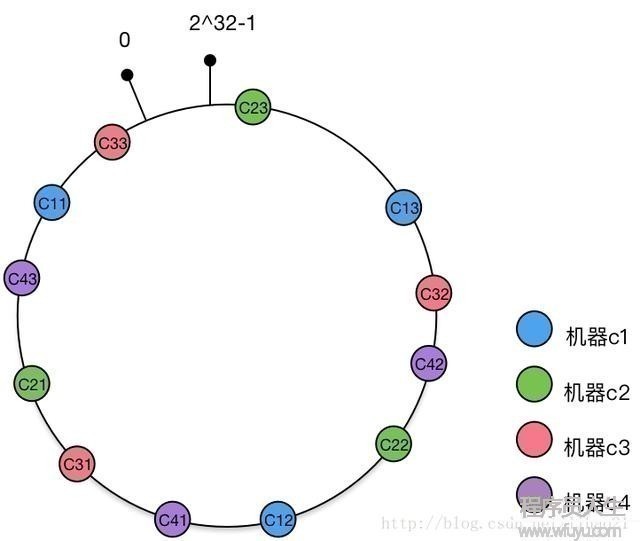
图10:机器c1,c2,c3,c4的1致性Hash环结构
新加入的缓存机器c4对应1组虚拟节点c41,c42,c43,加入到hash环后,影响的虚拟节点包括c31,c22,c11(顺时针查找到第1个节点),而这3个虚拟节点分别对应机器c3,c2,c1。即新加入的1台机器,同时影响到原本的3台机器。理想情况下,新加入的机器同等地分担了原有机器的负载,这正是虚拟节点带来的好处。而且新加入机器c4后,只影响25%(1/4)对象分配,也就是说,命中率依然有75%,这跟没有使用虚拟节点的1致性hash算法得到的结果是相同的。
总结
1致性hash算法解决了散布式环境下机器增加或减少时,简单的取模运算没法获得较高命中率的问题。通过虚拟节点的使用,1致性hash算法可以均匀分担机器的负载,使得这1算法更具现实的意义。正因如此,1致性hash算法被广泛利用于散布式系统中。
参考资料
https://en.wikipedia.org/wiki/Consistent_hashing
https://www.codeproject.com/articles/56138/consistent-hashing
《大型网站技术架构——核心原理与安全分析》,李智慧著,电子工业出版社

程序员人生,我编程,我富裕,记住wfuyu网,php教程,php学习,php手册,CMS模版制作
声明:本站大部分内容是作者原创,少部分收集于互联网供大家一起学习,原版权很多不明,如有侵权请联系本站,谢谢!
粤ICP备14040726号-1 2015-2020 程序员人生 版权所有


