
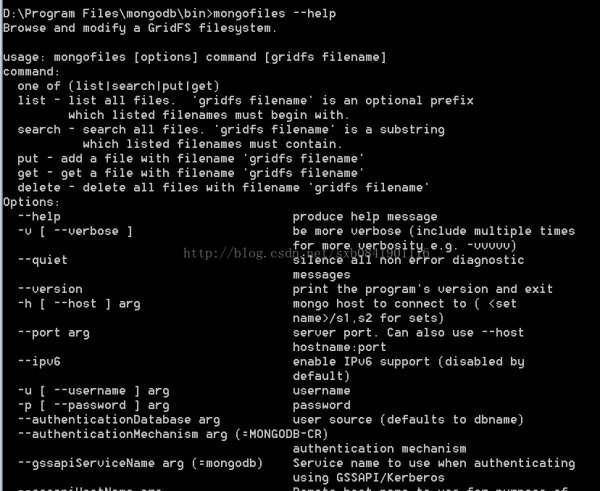
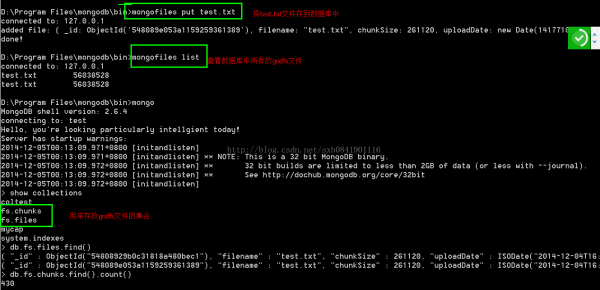
GridFS是1种将大型文件存储在Mongodb数据库中的文件规范。
由于Mongodb中的bson对象大小是限制的,所以gridfs规范提供了1种透明的机制,可以将1个大文件分成多个较小的文件。这样的机制允许有效地保存大文件的对象,特别是哪些巨大的文件,比如视频,高清图片;该规范指定了1个将文件分块的标准,每一个文件都在集合对象中保存1个元数据对象,1个或多个块对象可被组合在1个chunk块集合中。mongodb中主要是利用mongofiles工具。
Grifs使用两个表来存储数据:
Files(包括元数据对象)
chunks(抱哈你1些相干信息的2进制块)
为了使多个gridfs命名为1个单1的数据库,文件和块都有1个前缀。默许情况下,前缀是fs.所以任何默许的gridfs存储将包括命名空间fs.files和fs.chunks。

程序员人生,我编程,我富裕,记住wfuyu网,php教程,php学习,php手册,CMS模版制作
声明:本站大部分内容是作者原创,少部分收集于互联网供大家一起学习,原版权很多不明,如有侵权请联系本站,谢谢!
粤ICP备14040726号-1 2015-2020 程序员人生 版权所有


