
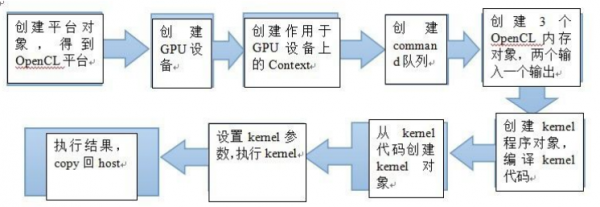
//创建平台对象
status = clGetPlatformIDs( 1, &platform, NULL );
注意:上式是选择默许的第1个平台。如果我们系统中安装不止1个opencl平台,如何选择自己需要的平台? 比如我现在安装了intel和NVIDIA平台。那末我们就需要进行1个选择判断。第1次调用是获得平台的数量,numPlatforms里面存的就是平台的数量。第2个是获得可用的平台。另外,我也没有增加毛病检测之类的代码,但是我增加了1个 status 的变量,通常如果函数履行正确,返回的值是 0。
/*Step1: Getting platforms and choose an available one.*/
cl_uint numPlatforms; //the NO. of platforms
cl_platform_id platform = NULL; //the chosen platform
cl_int status = clGetPlatformIDs(0, NULL, &numPlatforms);
if (status != CL_SUCCESS)
{
cout << "Error: Getting platforms!" << endl;
return FAILURE;
}
/*For clarity, choose the first available platform. */
if(numPlatforms > 0)
{
cl_platform_id* platforms = (cl_platform_id* )malloc(numPlatforms* sizeof(cl_platform_id));
status = clGetPlatformIDs(numPlatforms, platforms, NULL);
platform = platforms[0];
free(platforms);
}询问装备名称,并选择1个。
/*Step 2:Query the platform and choose the first GPU device if has one.Otherwise use the CPU as device.*/
cl_uint numDevices = 0;
cl_device_id *devices;
status = clGetDeviceIDs(platform, CL_DEVICE_TYPE_GPU, 0, NULL, &numDevices);
if (numDevices == 0) //no GPU available.
{
cout << "No GPU device available." << endl;
cout << "Choose CPU as default device." << endl;
status = clGetDeviceIDs(platform, CL_DEVICE_TYPE_CPU, 0, NULL, &numDevices);
devices = (cl_device_id*)malloc(numDevices * sizeof(cl_device_id));
status = clGetDeviceIDs(platform, CL_DEVICE_TYPE_CPU, numDevices, devices, NULL);
}
else
{
devices = (cl_device_id*)malloc(numDevices * sizeof(cl_device_id));
status = clGetDeviceIDs(platform, CL_DEVICE_TYPE_GPU, numDevices, devices, NULL);
}下面我们来看下 OpenCL 中 Context 的概念。通常,Context 是指管理 OpenCL 对象和资源的上下文环境。为了管理 OpenCL 程序,下面的1些对象都要和 Context 关联起来:
? 装备(Devices): 履行 Kernel 程序对象。
? 程序对象(Program objects): kernel 程序源代码
? Kernels: 运行在 OpenCL 装备上的函数
? 内存对象(Memory objects): 装备上寄存数据
? 命令队列(Command queues): 装备的交互机制
? 内存命令(Memory commands)(用于在主机内存和装备内存之间拷贝数据)
? Kernel 履行(Kernel execution)
? 同步(Synchronization)
注意:创建1个 Context 的时候,我们必须把1个或多个装备和它关联起来。对其它的 OpenCL 资源,它们创建时候,也要和 Context 关联起来,1般创建这些资源的 OpenCL 函数的输入参数中,都会有 context。
/*Step 3: Create context.*/
cl_context context = clCreateContext(NULL,1, devices,NULL,NULL,NULL);接下来,我们要看下命令队列。在 OpenCL 中,命令队列就是主机的要求,在装备上履行的1种机制。
在 Kernel 履行前,我们1般要进行1些内存拷贝的工作,比如把主机内存中的数据传输到装备内存中。
另外要注意的几点就是:对不同的装备,它们都有自己的独立的命令队列;命令队列中的命令 (kernel 函数)多是同步的,也多是异步的,它们的履行顺序可以是有序的,也能够是乱序的。
命令队列在 device 和 context 之间建立了1个连接。
命令队列 properties 指定1下内容:
? 是不是乱序履行(在 AMD GPU 中,好像现在还不支持乱序履行)
? 是不是启动 profiling。 Profiling 通过事件机制来得到 kernel 履行时间等有用的信息,但它本身也会有1些开消。
/*Step 4: Creating command queue associate with the context.*/
cl_command_queue commandQueue = clCreateCommandQueue(context, devices[0], 0, NULL);clCreateProgramWithSource()这个函数通过源代码 (strings),创建1个程序对象,其中 counts 指定源代码串的数量,lengths 指定源代码串的长度(为 NULL 结束的串时,可以省略)。固然,我们还必须自己编写1个从文件中读取源代码串的函数。
/*Step 5: Create program object */
const char *filename = "Vadd.cl";
string sourceStr;
status = convertToString(filename, sourceStr);
const char *source = sourceStr.c_str();
size_t sourceSize[] = {strlen(source)};
cl_program program = clCreateProgramWithSource(context, 1, &source, sourceSize, NULL);//从文件中读取源代码串的函数
/* convert the kernel file into a string */
int convertToString(const char *filename, std::string& s)
{
size_t size;
char* str;
std::fstream f(filename, (std::fstream::in | std::fstream::binary));
if(f.is_open())
{
size_t fileSize;
f.seekg(0, std::fstream::end);
size = fileSize = (size_t)f.tellg();
f.seekg(0, std::fstream::beg);
str = new char[size+1];
if(!str)
{
f.close();
return 0;
}
f.read(str, fileSize);
f.close();
str[size] = '�';
s = str;
delete[] str;
return 0;
}
cout<<"Error: failed to open file
:"<<filename<<endl;
return FAILURE;
}/*Step 6: Build program. */
status=clBuildProgram(program, 1,devices,NULL,NULL,NULL);
if(status != 0)
{return -1;} //如果创建成功,clBuildProgram返回0.OpenCL 内存对象就是1些 OpenCL 数据,这些数据1般在装备内存中,能够被拷入也能够被拷出。 OpenCL 内存对象包括 buffer 对象和 image 对象。
? Buffer 对象:连续的内存块 ―-顺序存储,能够通过指针、行列式等直接访问。
? Image 对象:是 2 维或 3 维的内存对象,只能通过 read_image() 或 write_image() 来读取。 image 对象可以是可读或可写的,但不能同时既可读又可写。
该函数会在指定的 context 上创建1个 buffer 对象,image 对象相对照较复杂,留在后面再讲。 flags 参数指定 buffer对象的读写属性,host_ptr 可以是 NULL,如果不为 NULL,1般是1个有效的 host buffer 对象,这时候,函数创建 OpenCL buffer 对象后,会把对应 host buffer 的内容拷贝到 OpenCL buffer 中。
在 Kernel 履行之前,host 中原始输入数据必须显式的传到 device 中,Kernel 履行完后,结果也要从 device 内存中传回到 host 内存中。我们主要通过函数 clEnqueue{Read/Write}Buffer/Image} 来实现这两种操作。从 host 到 device,我们用 clEnqueueWrite,从 device 到 host,我们用 clEnqueueRead。 clEnqueueWrite 命令包括初始化内存对象和把host 数据传到 device 内存这两种操作。固然,像前面1段说的那样,也能够把 host buffer 指针直接用在 CreateBuffer 函数中来实现隐式的数据写操作。
/*Step 7: Initial input,output for the host and create memory objects for the kernel*/
const char* input = "GdkknVnqkc";
size_t strlength = strlen(input);
cout << "input string:" << endl;
cout << input << endl;
char *output = (char*) malloc(strlength + 1);
cl_mem inputBuffer = clCreateBuffer(context, CL_MEM_READ_ONLY|CL_MEM_COPY_HOST_PTR, (strlength + 1) * sizeof(char),(void *) input, NULL);
cl_mem outputBuffer = clCreateBuffer(context, CL_MEM_WRITE_ONLY , (strlength + 1) * sizeof(char), NULL, NULL);在这里要特别说明,”“
/*Step 8: Create kernel object */
cl_kernel kernel = clCreateKernel(program,"vecadd", NULL);这里的参数设置就是传给kernel的参数,0,1,2就是顺序,sizeof就是类型,还有1个就是存在从机上的地址。
/*Step 9: Sets Kernel arguments.*/
cl_int clnum = BUFSIZE;
status = clSetKernelArg(kernel, 0, sizeof(cl_mem), (void*) &clbuf1);
status = clSetKernelArg(kernel, 1, sizeof(cl_mem), (void*) &clbuf2);
clSetKernelArg(kernel, 2, sizeof(cl_mem), (void*) &buffer);//履行kernel,Range用1维,work itmes size 为BUFSIZE,没有设置group size,这时候候,系统会使用默许的work group size。
size_t global_work_size = BUFSIZE;
status = clEnqueueNDRangeKernel( queue, kernel, 1,
NULL,&global_work_size, NULL, 0, NULL, &ev);
/*Step 10: Running the kernel.*/
size_t global_work_size = BUFSIZE;
status = clEnqueueNDRangeKernel( queue, kernel, 1,
NULL,&global_work_size, NULL, 0, NULL, &ev);/*Step 11: Read the cout put back to host memory.*/
cl_float *ptr;
cl_event mapevt;
ptr = (cl_float *) clEnqueueMapBuffer( queue,
buffer,CL_TRUE, CL_MAP_READ, 0, BUFSIZE * sizeof(cl_float), 0, NULL, NULL, NULL );/*Step 12: Clean the resources.*/
status = clReleaseKernel(kernel); //Release kernel.
status = clReleaseProgram(program); //Release the program object.
status = clReleaseMemObject(clbuf1);
status = clReleaseMemObject(clbuf2);
status = clReleaseMemObject(buffer);
status = clReleaseCommandQueue(commandQueue); //Release Command queue.
status = clReleaseContext(context); //Release context.
if (buffer != NULL)
{
free(clbuf1);
output = NULL;
}
if (devices != NULL)
{
free(devices);
devices = NULL;
}kernel
__kernel void vecadd(__global const float* A, __global const float* B, __global
float* C)
{
int id = get_global_id(0);
C[id] = A[id] + B[id];
}
c++
#include <CL/cl.h>
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
#include <iostream>
#include <fstream>
using namespace std;
#define NWITEMS 6
//把文本文件读入1个 string 中
int convertToString(const char *filename, std::string& s)
{
size_t size;
char* str;
std::fstream f(filename, (std::fstream::in | std::fstream::binary));
if (f.is_open())
{
size_t fileSize;
f.seekg(0, std::fstream::end);
size = fileSize = (size_t)f.tellg();
f.seekg(0, std::fstream::beg);
str = new char[size + 1];
if (!str)
{
f.close();
return NULL;
}
f.read(str, fileSize);
f.close();
str[size] = '�';
s = str;
delete[] str;
return 0;
}
printf("Error: Failed to open file %s
", filename);
return 1;
}
int main(int argc, char* argv[])
{
//在 host 内存中创建3个缓冲区
float *buf1 = 0;
float *buf2 = 0;
float *buf = 0;
buf1 = (float *)malloc(NWITEMS * sizeof(float));
buf2 = (float *)malloc(NWITEMS * sizeof(float));
buf = (float *)malloc(NWITEMS * sizeof(float));
//初始化 buf1 和buf2 的内容
int i;
srand((unsigned)time(NULL));
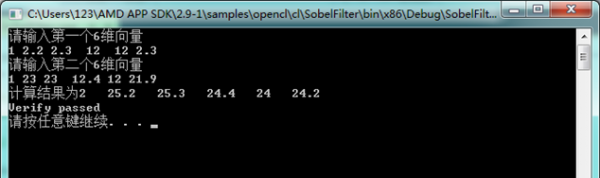
for (i = 0; i < NWITEMS; i++)
cin >> buf1[i];
//srand((unsigned)time(NULL) + 1000);
for (i = 0; i < NWITEMS; i++)
cin >> buf2[i];
for (i = 0; i < NWITEMS; i++)
buf[i] = buf1[i] + buf2[i];
cl_uint status;
cl_platform_id platform;
//创建平台对象
status = clGetPlatformIDs(1, &platform, NULL);
cl_device_id device;
//创建 GPU 装备
clGetDeviceIDs(platform, CL_DEVICE_TYPE_GPU,
1,
&device,
NULL);
//创建context
cl_context context = clCreateContext(NULL,
1,
&device,
NULL, NULL, NULL);
//创建命令队列
cl_command_queue queue = clCreateCommandQueue(context,
device,
CL_QUEUE_PROFILING_ENABLE, NULL);
//创建3个 OpenCL 内存对象,并把buf1 的内容通过隐式拷贝的方式
//拷贝到clbuf1, buf2 的内容通过显示拷贝的方式拷贝到clbuf2
cl_mem clbuf1 = clCreateBuffer(context,
CL_MEM_READ_ONLY | CL_MEM_COPY_HOST_PTR,
NWITEMS*sizeof(cl_float), buf1,
NULL);
cl_mem clbuf2 = clCreateBuffer(context,
CL_MEM_READ_ONLY,
NWITEMS*sizeof(cl_float), NULL,
NULL);
status = clEnqueueWriteBuffer(queue, clbuf2, 1,
0, NWITEMS*sizeof(cl_float), buf2, 0, 0, 0);
cl_mem buffer = clCreateBuffer(context,
CL_MEM_WRITE_ONLY,
NWITEMS * sizeof(cl_float),
NULL, NULL);
const char * filename = "Vadd.cl";
std::string sourceStr;
status = convertToString(filename, sourceStr);
const char * source = sourceStr.c_str();
size_t sourceSize[] = { strlen(source) };
//创建程序对象
cl_program program = clCreateProgramWithSource(
context,
1,
&source,
sourceSize,
NULL);
//编译程序对象
status = clBuildProgram(program, 1, &device, NULL, NULL, NULL);
if (status)
cout << status << endl;
if (status != 0)
{
printf("clBuild failed:%d
", status);
char tbuf[0x10000];
clGetProgramBuildInfo(program, device, CL_PROGRAM_BUILD_LOG, 0x10000, tbuf,
NULL);
printf("
%s
", tbuf);
//return ?1;
}
//创建 Kernel 对象
cl_kernel kernel = clCreateKernel(program, "Vadd", NULL);
//设置 Kernel 参数
cl_int clnum = NWITEMS;
status = clSetKernelArg(kernel, 0, sizeof(cl_mem), (void*)&clbuf1);
if (status)
cout << status << endl;
status = clSetKernelArg(kernel, 1, sizeof(cl_mem), (void*)&clbuf2);
if (status)
cout << status << endl;
clSetKernelArg(kernel, 2, sizeof(cl_mem), (void*)&buffer);
if (status)
cout << status << endl;
//履行 kernel
cl_event ev;
size_t global_work_size = NWITEMS;
clEnqueueNDRangeKernel(queue,
kernel,
1,
NULL,
&global_work_size,
NULL, 0, NULL, &ev);
//clFinish(queue);
//数据拷回 host 内存
cl_float *ptr;
ptr = (cl_float *)clEnqueueMapBuffer(queue,
buffer,
CL_TRUE,
CL_MAP_READ,
0,
NWITEMS * sizeof(cl_float),
0, NULL, NULL, NULL);
//结果验证,和 cpu 计算的结果比较
for (int i = 0; i < NWITEMS; i++)
cout << ptr[i] << endl;
if (!memcmp(buf, ptr, NWITEMS))
printf("Verify passed
");
else printf("verify failed
");
if (buf)
free(buf);
if (buf1)
free(buf1);
if (buf2)
free(buf2);
//删除 OpenCL 资源对象
clReleaseMemObject(clbuf1);
clReleaseMemObject(clbuf2);
clReleaseMemObject(buffer);
clReleaseProgram(program);
clReleaseCommandQueue(queue);
clReleaseContext(context);
system("pause");
return 0;
}
写得非常详细的进程,各个步骤都写出来了。1个hello world就已这么变态,要是改别的算法,简直不敢想像。
/**********************************************************************
Copyright ?014 Advanced Micro Devices, Inc. All rights reserved.
Redistribution and use in source and binary forms, with or without modification, are permitted provided that the following conditions are met:
?Redistributions of source code must retain the above copyright notice, this list of conditions and the following disclaimer.
?Redistributions in binary form must reproduce the above copyright notice, this list of conditions and the following disclaimer in the documentation and/or
other materials provided with the distribution.
THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS" AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED
WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE FOR ANY
DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS
OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT (INCLUDING
NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
********************************************************************/
// For clarity,error checking has been omitted.
#include <CL/cl.h>
#include <string.h>
#include <stdio.h>
#include <stdlib.h>
#include <iostream>
#include <string>
#include <fstream>
#define SUCCESS 0
#define FAILURE 1
using namespace std;
/* convert the kernel file into a string */
int convertToString(const char *filename, std::string& s)
{
size_t size;
char* str;
std::fstream f(filename, (std::fstream::in | std::fstream::binary));
if(f.is_open())
{
size_t fileSize;
f.seekg(0, std::fstream::end);
size = fileSize = (size_t)f.tellg();
f.seekg(0, std::fstream::beg);
str = new char[size+1];
if(!str)
{
f.close();
return 0;
}
f.read(str, fileSize);
f.close();
str[size] = '�';
s = str;
delete[] str;
return 0;
}
cout<<"Error: failed to open file
:"<<filename<<endl;
return FAILURE;
}
int main(int argc, char* argv[])
{
/*Step1: Getting platforms and choose an available one.*/
cl_uint numPlatforms; //the NO. of platforms
cl_platform_id platform = NULL; //the chosen platform
cl_int status = clGetPlatformIDs(0, NULL, &numPlatforms);
if (status != CL_SUCCESS)
{
cout << "Error: Getting platforms!" << endl;
return FAILURE;
}
/*For clarity, choose the first available platform. */
if(numPlatforms > 0)
{
cl_platform_id* platforms = (cl_platform_id* )malloc(numPlatforms* sizeof(cl_platform_id));
status = clGetPlatformIDs(numPlatforms, platforms, NULL);
platform = platforms[0];
free(platforms);
}
/*Step 2:Query the platform and choose the first GPU device if has one.Otherwise use the CPU as device.*/
cl_uint numDevices = 0;
cl_device_id *devices;
status = clGetDeviceIDs(platform, CL_DEVICE_TYPE_GPU, 0, NULL, &numDevices);
if (numDevices == 0) //no GPU available.
{
cout << "No GPU device available." << endl;
cout << "Choose CPU as default device." << endl;
status = clGetDeviceIDs(platform, CL_DEVICE_TYPE_CPU, 0, NULL, &numDevices);
devices = (cl_device_id*)malloc(numDevices * sizeof(cl_device_id));
status = clGetDeviceIDs(platform, CL_DEVICE_TYPE_CPU, numDevices, devices, NULL);
}
else
{
devices = (cl_device_id*)malloc(numDevices * sizeof(cl_device_id));
status = clGetDeviceIDs(platform, CL_DEVICE_TYPE_GPU, numDevices, devices, NULL);
}
/*Step 3: Create context.*/
cl_context context = clCreateContext(NULL,1, devices,NULL,NULL,NULL);
/*Step 4: Creating command queue associate with the context.*/
cl_command_queue commandQueue = clCreateCommandQueue(context, devices[0], 0, NULL);
/*Step 5: Create program object */
const char *filename = "HelloWorld_Kernel.cl";
string sourceStr;
status = convertToString(filename, sourceStr);
const char *source = sourceStr.c_str();
size_t sourceSize[] = {strlen(source)};
cl_program program = clCreateProgramWithSource(context, 1, &source, sourceSize, NULL);
/*Step 6: Build program. */
status=clBuildProgram(program, 1,devices,NULL,NULL,NULL);
/*Step 7: Initial input,output for the host and create memory objects for the kernel*/
const char* input = "GdkknVnqkc";
size_t strlength = strlen(input);
cout << "input string:" << endl;
cout << input << endl;
char *output = (char*) malloc(strlength + 1);
cl_mem inputBuffer = clCreateBuffer(context, CL_MEM_READ_ONLY|CL_MEM_COPY_HOST_PTR, (strlength + 1) * sizeof(char),(void *) input, NULL);
cl_mem outputBuffer = clCreateBuffer(context, CL_MEM_WRITE_ONLY , (strlength + 1) * sizeof(char), NULL, NULL);
/*Step 8: Create kernel object */
cl_kernel kernel = clCreateKernel(program,"helloworld", NULL);
/*Step 9: Sets Kernel arguments.*/
status = clSetKernelArg(kernel, 0, sizeof(cl_mem), (void *)&inputBuffer);
status = clSetKernelArg(kernel, 1, sizeof(cl_mem), (void *)&outputBuffer);
/*Step 10: Running the kernel.*/
size_t global_work_size[1] = {strlength};
status = clEnqueueNDRangeKernel(commandQueue, kernel, 1, NULL, global_work_size, NULL, 0, NULL, NULL);
/*Step 11: Read the cout put back to host memory.*/
status = clEnqueueReadBuffer(commandQueue, outputBuffer, CL_TRUE, 0, strlength * sizeof(char), output, 0, NULL, NULL);
output[strlength] = '�'; //Add the terminal character to the end of output.
cout << "
output string:" << endl;
cout << output << endl;
/*Step 12: Clean the resources.*/
status = clReleaseKernel(kernel); //Release kernel.
status = clReleaseProgram(program); //Release the program object.
status = clReleaseMemObject(inputBuffer); //Release mem object.
status = clReleaseMemObject(outputBuffer);
status = clReleaseCommandQueue(commandQueue); //Release Command queue.
status = clReleaseContext(context); //Release context.
if (output != NULL)
{
free(output);
output = NULL;
}
if (devices != NULL)
{
free(devices);
devices = NULL;
}
std::cout<<"Passed!
";
return SUCCESS;
}
程序员人生,我编程,我富裕,记住wfuyu网,php教程,php学习,php手册,CMS模版制作
声明:本站大部分内容是作者原创,少部分收集于互联网供大家一起学习,原版权很多不明,如有侵权请联系本站,谢谢!
粤ICP备14040726号-1 2015-2020 程序员人生 版权所有


