
继续Flink Fault Tolerance机制剖析。上1篇文章我们结合代码讲授了Flink中检查点是如何利用的(如何根据快照做失败恢复,和检查点被利用的场景),这篇我们来谈谈检查点的触发机制和基于Actor的消息驱动的协同机制。这篇触及到1个非常关键的类——CheckpointCoordinator。
org.apache.flink.runtime.checkpoint.CheckpointCoordinator
该类可以理解为检查点的调和器,用来调和operator和state的散布式快照。
检查点的触发机制是基于定时器的周期性触发。这触及到1个定时器的实现类ScheduledTrigger
触发检查点的定时任务类。其实现就是调用triggerCheckpoint方法。这个方法后面会具体介绍。
public void run() {
try {
triggerCheckpoint(System.currentTimeMillis());
}
catch (Exception e) {
LOG.error("Exception while triggering checkpoint", e);
}
}启动触发检查点的定时任务的方法实现:
public void startCheckpointScheduler() {
synchronized (lock) {
if (shutdown) {
throw new IllegalArgumentException("Checkpoint coordinator is shut down");
}
// make sure all prior timers are cancelled
stopCheckpointScheduler();
try {
// Multiple start calls are OK
checkpointIdCounter.start();
} catch (Exception e) {
String msg = "Failed to start checkpoint ID counter: " + e.getMessage();
throw new RuntimeException(msg, e);
}
periodicScheduling = true;
currentPeriodicTrigger = new ScheduledTrigger();
timer.scheduleAtFixedRate(currentPeriodicTrigger, baseInterval, baseInterval);
}
}方法的实现包括两个主要动作:
checkpointIdCounter关闭定时任务的方法,用来释放资源,重置1些标记变量。
该方法是触发1个新的检查点的核心逻辑。
首先,方法中会去判断1个flag:triggerRequestQueued。该标识表示是不是1个检查点的触发要求不能被立即履行。
// sanity check: there should never be more than one trigger request queued
if (triggerRequestQueued) {
LOG.warn("Trying to trigger another checkpoint while one was queued already");
return false;
}如果不能被立即履行,则直接返回。
不能被立即履行的缘由是:还有其他处理没有完成。
接着检查正在并发处理的未完成的检查点:
// if too many checkpoints are currently in progress, we need to mark that a request is queued
if (pendingCheckpoints.size() >= maxConcurrentCheckpointAttempts) {
triggerRequestQueued = true;
if (currentPeriodicTrigger != null) {
currentPeriodicTrigger.cancel();
currentPeriodicTrigger = null;
}
return false;
}如果未完成的检查点过量,大于允许的并发处理的检查点数目的阈值,则将当前检查点的触发要求设置为不能立即履行,如果定时任务已启动,则取消定时任务的履行,并返回。
以上这些检查处于基于锁机制实现的同步代码块中。
接着检查需要被触发检查点的task是不是都处于运行状态:
ExecutionAttemptID[] triggerIDs = new ExecutionAttemptID[tasksToTrigger.length];
for (int i = 0; i < tasksToTrigger.length; i++) {
Execution ee = tasksToTrigger[i].getCurrentExecutionAttempt();
if (ee != null && ee.getState() == ExecutionState.RUNNING) {
triggerIDs[i] = ee.getAttemptId();
} else {
LOG.info("Checkpoint triggering task {} is not being executed at the moment. Aborting checkpoint.",
tasksToTrigger[i].getSimpleName());
return false;
}
}只要有1个task不满足条件,则不会触发检查点,并立即返回。
然后检查是不是所有需要ack检查点的task都处于运行状态:
Map<ExecutionAttemptID, ExecutionVertex> ackTasks = new HashMap<>(tasksToWaitFor.length);
for (ExecutionVertex ev : tasksToWaitFor) {
Execution ee = ev.getCurrentExecutionAttempt();
if (ee != null) {
ackTasks.put(ee.getAttemptId(), ev);
} else {
LOG.info("Checkpoint acknowledging task {} is not being executed at the moment. Aborting checkpoint.",
ev.getSimpleName());
return false;
}
}如果有1个task不满足条件,则不会触发检查点,并立即返回。
以上条件都满足(即没有return false;),才具有触发1个检查点的基本条件。
下1步,取得checkpointId:
final long checkpointID;
if (nextCheckpointId < 0) {
try {
// this must happen outside the locked scope, because it communicates
// with external services (in HA mode) and may block for a while.
checkpointID = checkpointIdCounter.getAndIncrement();
}
catch (Throwable t) {
int numUnsuccessful = ++numUnsuccessfulCheckpointsTriggers;
LOG.warn("Failed to trigger checkpoint (" + numUnsuccessful + " consecutive failed attempts so far)", t);
return false;
}
}
else {
checkpointID = nextCheckpointId;
}这依赖于该方法的另外一个参数nextCheckpointId,如果其值为⑴,则起到标识的作用,唆使checkpointId将从外部获得(比如Zookeeper,后续文章会谈及检查点ID的生成机制)。
接着创建1个PendingCheckpoint对象:
final PendingCheckpoint checkpoint = new PendingCheckpoint(job, checkpointID, timestamp, ackTasks);该类表示1个待处理的检查点。
与此同时,会定义1个针对当前检查点超时进行资源清算的取消器canceller。该取消器主要是针对检查点没有释放资源的情况进行资源释放操作,同时还会调用triggerQueuedRequests方法启动1个触发检查点的定时任务,如果有的话(取决于triggerRequestQueued是不是为true)。
然后会再次进入同步代码段,对上面的是不是新建检查点的判断条件做2次检查,避免产生竞态条件。这里做2次检查的缘由是,中间有1段关于取得checkpointId的代码,不在同步块中。
检查后,如果触发检查点的条件依然是满足的,那末将上面创建的PendingCheckpoint对象加入集合中:
pendingCheckpoints.put(checkpointID, checkpoint);同时会启动针对当前检查点的超时取消器:
timer.schedule(canceller, checkpointTimeout);接下来会发送消息给task以真正触发检查点(基于消息驱动的协同机制):
for (int i = 0; i < tasksToTrigger.length; i++) {
ExecutionAttemptID id = triggerIDs[i];
TriggerCheckpoint message = new TriggerCheckpoint(job, id, checkpointID, timestamp);
tasksToTrigger[i].sendMessageToCurrentExecution(message, id);
}上面已谈到了检查点的触发机制是基于定时任务的周期性触发,那末定时任务的启停机制又是甚么?Flink使用的是基于AKKA的Actor模型的消息驱动机制。
类CheckpointCoordinatorDeActivator是1个Actor的实现,它用于基于消息来驱动检查点的定时任务的启停:
public void handleMessage(Object message) {
if (message instanceof ExecutionGraphMessages.JobStatusChanged) {
JobStatus status = ((ExecutionGraphMessages.JobStatusChanged) message).newJobStatus();
if (status == JobStatus.RUNNING) {
// start the checkpoint scheduler
coordinator.startCheckpointScheduler();
} else {
// anything else should stop the trigger for now
coordinator.stopCheckpointScheduler();
}
}
// we ignore all other messages
}该Actor会收到Job状态的变化通知:JobStatusChanged。1旦变成RUNNING,那末检查点的定时任务会被立即启动;否则会被立即关闭。
该Actor被创建的代码是CheckpointCoordinator中的createActivatorDeactivator方法:
public ActorGateway createActivatorDeactivator(ActorSystem actorSystem, UUID leaderSessionID) {
synchronized (lock) {
if (shutdown) {
throw new IllegalArgumentException("Checkpoint coordinator is shut down");
}
if (jobStatusListener == null) {
Props props = Props.create(CheckpointCoordinatorDeActivator.class, this, leaderSessionID);
// wrap the ActorRef in a AkkaActorGateway to support message decoration
jobStatusListener = new AkkaActorGateway(actorSystem.actorOf(props), leaderSessionID);
}
return jobStatusListener;
}
}既然,是基于消息驱动机制,那末就需要各种类型的消息对应不同的业务逻辑。这些消息在Flink中被定义在package:org.apache.flink.runtime.messages.checkpoint中。
类图以下:
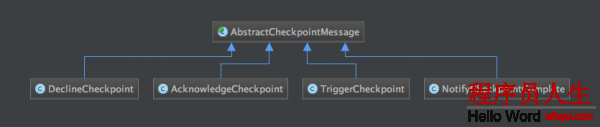
检查点消息的基础抽象类,提供了3个公共属性(从构造器注入):
JobID的实例,表示当前这条消息实例的归属;ExecutionAttemptID的实例,表示检查点的源/目的任务除此以外,该实现仅仅override了hashCode和equals方法。
该消息由JobManager发送给TaskManager,用于告知1个task触发它的检查点。
位于CheckpointCoordinator类的triggerCheckpoint中,上面已提及过。
for (int i = 0; i < tasksToTrigger.length; i++) {
ExecutionAttemptID id = triggerIDs[i];
TriggerCheckpoint message = new TriggerCheckpoint(job, id, checkpointID, timestamp);
tasksToTrigger[i].sendMessageToCurrentExecution(message, id);
}TaskManager的handleCheckpointingMessage实现:
case message: TriggerCheckpoint =>
val taskExecutionId = message.getTaskExecutionId
val checkpointId = message.getCheckpointId
val timestamp = message.getTimestamp
log.debug(s"Receiver TriggerCheckpoint $checkpointId@$timestamp for $taskExecutionId.")
val task = runningTasks.get(taskExecutionId)
if (task != null) {
task.triggerCheckpointBarrier(checkpointId, timestamp)
} else {
log.debug(s"TaskManager received a checkpoint request for unknown task $taskExecutionId.")
}主要是触发检查点屏障Barrier。
该消息由TaskManager发送给JobManager,用于告知检查点调和器:检查点的要求还没有能够被处理。这类情况通常产生于:某task已处于RUNNING状态,但在内部可能还没有准备好履行检查点。
它除AbstractCheckpointMessage需要的3个属性外,还需要用于关联检查点的timestamp。
位于Task类的triggerCheckpointBarrier方法中:
Runnable runnable = new Runnable() {
@Override
public void run() {
try {
boolean success = statefulTask.triggerCheckpoint(checkpointID, checkpointTimestamp);
if (!success) {
DeclineCheckpoint decline = new DeclineCheckpoint(jobId, getExecutionId(), checkpointID, checkpointTimestamp);
jobManager.tell(decline);
}
}
catch (Throwable t) {
if (getExecutionState() == ExecutionState.RUNNING) {
failExternally(new RuntimeException(
"Error while triggering checkpoint for " + taskName,
t));
}
}
}
};位于JobManager的handleCheckpointMessage中
具体的实现在CheckpointCoordinator的receiveDeclineMessage中:
首先从接收的消息中(DeclineCheckpoint)取得检查点编号:
final long checkpointId = message.getCheckpointId();接下来的逻辑是判断当前检查点是不是是未完成的检查点:isPendingCheckpoint
接下来分为3种情况对待:
discarded)isPendingCheckpoint = true;
pendingCheckpoints.remove(checkpointId);
checkpoint.discard(userClassLoader);
rememberRecentCheckpointId(checkpointId);置isPendingCheckpoint为true,根据检查点编号,将检查点从未完成的检查点集合中移除,discard检查点,记住最近的检查点(将其保持到到1个最近的检查点列表中)。
接下来查找是不是还有待处理的检查点,根据检查点时间戳来判断:
boolean haveMoreRecentPending = false;
Iterator<Map.Entry<Long, PendingCheckpoint>> entries = pendingCheckpoints.entrySet().iterator();
while (entries.hasNext()) {
PendingCheckpoint p = entries.next().getValue();
if (!p.isDiscarded() && p.getCheckpointTimestamp() >= checkpoint.getCheckpointTimestamp()) {
haveMoreRecentPending = true;
break;
}
}根据标识haveMoreRecentPending来进入不同的处理逻辑:
if (!haveMoreRecentPending && !triggerRequestQueued) {
LOG.info("Triggering new checkpoint because of discarded checkpoint " + checkpointId);
triggerCheckpoint(System.currentTimeMillis());
} else if (!haveMoreRecentPending) {
LOG.info("Promoting queued checkpoint request because of discarded checkpoint " + checkpointId);
triggerQueuedRequests();
}如果有需要处理的检查点,并且当前能立即处理,则立即触发检查点定时任务;如果有需要处理的检查点,但不能立即处理,则触发入队的定时任务。
discarded抛出IllegalStateException异常
如果在最近未完成的检查点列表中找到,则有可能表示消息来迟了,将isPendingCheckpoint置为true,否则将isPendingCheckpoint置为false.
最后返回isPendingCheckpoint。
该消息是1个应对信号,表示某个独立的task的检查点已完成。也是由TaskManager发送给JobManager。该消息会携带task的状态:
RuntimeEnvironment类的acknowledgeCheckpoint方法。
具体的实现在CheckpointCoordinator的receiveAcknowledgeMessage中,开始的实现同receiveDeclineMessage,也是判断当前接收到的消息中包括的检查点是不是是待处理的检查点。如果是,并且也没有discard掉,则履行以下逻辑:
if (checkpoint.acknowledgeTask(message.getTaskExecutionId(), message.getState(), message.getStateSize())) {
if (checkpoint.isFullyAcknowledged()) {
completed = checkpoint.toCompletedCheckpoint();
completedCheckpointStore.addCheckpoint(completed);
LOG.info("Completed checkpoint " + checkpointId + " (in " +
completed.getDuration() + " ms)");
LOG.debug(completed.getStates().toString());
pendingCheckpoints.remove(checkpointId);
rememberRecentCheckpointId(checkpointId);
dropSubsumedCheckpoints(completed.getTimestamp());
onFullyAcknowledgedCheckpoint(completed);
triggerQueuedRequests();
}
}检查点首先应对相干的task,如果检查点已完全应对完成,则将检查点转换成CompletedCheckpoint,然后将其加入completedCheckpointStore列表,并从pendingCheckpoints中移除。然后调用dropSubsumedCheckpoints它会从pendingCheckpoints中diacard所有时间戳小于当前检查点的时间戳,并从集合中移除。
最后,如果该检查点被转化为已完成的检查点,则:
if (completed != null) {
final long timestamp = completed.getTimestamp();
for (ExecutionVertex ev : tasksToCommitTo) {
Execution ee = ev.getCurrentExecutionAttempt();
if (ee != null) {
ExecutionAttemptID attemptId = ee.getAttemptId();
NotifyCheckpointComplete notifyMessage = new NotifyCheckpointComplete(job, attemptId, checkpointId, timestamp);
ev.sendMessageToCurrentExecution(notifyMessage, ee.getAttemptId());
}
}
statsTracker.onCompletedCheckpoint(completed);
}迭代所有待commit的task,发送NotifyCheckpointComplete消息。同时触发状态跟踪器的onCompletedCheckpoint回调方法。
该消息由JobManager发送给TaskManager,用于告知1个task它的检查点已得到完成确认,task可以向第3方提交该检查点。
位于CheckpointCoordinator类的receiveAcknowledgeMessage方法中,当检查点acktask完成,转化为CompletedCheckpoint以后
if (completed != null) {
final long timestamp = completed.getTimestamp();
for (ExecutionVertex ev : tasksToCommitTo) {
Execution ee = ev.getCurrentExecutionAttempt();
if (ee != null) {
ExecutionAttemptID attemptId = ee.getAttemptId();
NotifyCheckpointComplete notifyMessage = new NotifyCheckpointComplete(job, attemptId, checkpointId, timestamp);
ev.sendMessageToCurrentExecution(notifyMessage, ee.getAttemptId());
}
}
statsTracker.onCompletedCheckpoint(completed);
}TaskManager的handleCheckpointingMessage
实现:
case message: NotifyCheckpointComplete =>
val taskExecutionId = message.getTaskExecutionId
val checkpointId = message.getCheckpointId
val timestamp = message.getTimestamp
log.debug(s"Receiver ConfirmCheckpoint $checkpointId@$timestamp for $taskExecutionId.")
val task = runningTasks.get(taskExecutionId)
if (task != null) {
task.notifyCheckpointComplete(checkpointId)
} else {
log.debug(
s"TaskManager received a checkpoint confirmation for unknown task $taskExecutionId.")
}主要是触发task的notifyCheckpointComplete方法。
这篇文章主要讲授了检查点的基于定时任务的周期性的触发机制,和基于Akka的Actor模型的消息驱动的协同处理机制。
微信扫码关注公众号:Apache_Flink

QQ扫码关注QQ群:Apache Flink学习交换群(123414680)

上一篇 联合训练图论场
下一篇 这是一个盗版和强盗的社会
程序员人生,我编程,我富裕,记住wfuyu网,php教程,php学习,php手册,CMS模版制作
声明:本站大部分内容是作者原创,少部分收集于互联网供大家一起学习,原版权很多不明,如有侵权请联系本站,谢谢!
粤ICP备14040726号-1 2015-2020 程序员人生 版权所有


