【Python数据挖掘课程】一.安装Python及爬虫入门介绍
来源:程序员人生 发布时间:2016-12-14 09:03:05 阅读次数:5597次
最近由于需要给大数据金融学院的学生讲授《Python数据发掘及大数据分析》的课程,所以在这里,我将结合自己的上课内容,详细讲授每一个步骤。作为助教,我更希望这门课程以实战为主,同时按小组划分学生,每一个小组最后都提交1个基于Python的数据发掘及大数据分析相干的成果。但是前面这节课没有在机房上,所以我在CSDN也将开设1个专栏,用于对该课程的补充。
希望该文章对你有所帮助,特别是对大数据或数据发掘的初学者,很开心和夏博、小民1起分享该课程,上课的感觉真的挺不错的,挺享受的。我也将认真对待每个我的学生,真的好想把自己的所学的所有知识都给予你们。同时由于学生来自不同的学院,有的乃至没有接触过编程,所以这门课程也将采取从零单排的情势讲述。
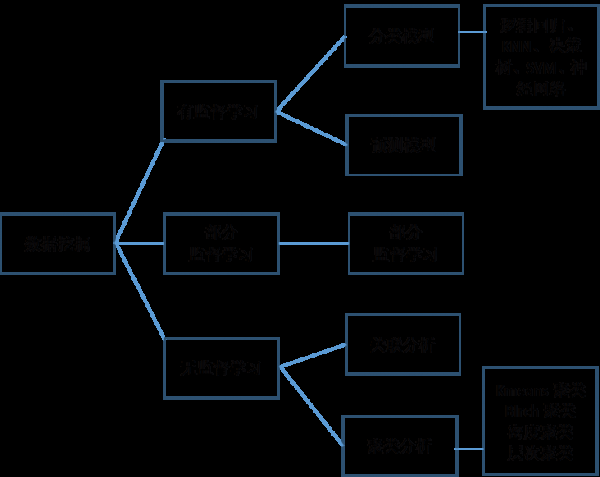
这门课程围绕下图所示的内容进行展开及实战。
课程资源:
1. 大数据及数据发掘基础
第1部份主要简单介绍3个问题(觉得无聊的直接调至第2部份):
1、甚么是大数据?
2、甚么是数据发掘?
3、大数据和数据发掘的区分?
由于前面几节课老师普及了大数据等1些基础知识,这里我并没有详细介绍,只是给几张图片,让大家简单了解下大数据和数据发掘相干的基础概念,我分享更多的是实战和编程。
<1>.大数据(Big Data)
大数据(big data)指没法在1定时间范围内用常规软件工具进行捕捉、管理和处理的数据集合,是需要新处理模式才能具有更强的决策力、洞察发现力和流程优化能力来适应海量、高增长率和多样化的信息资产。
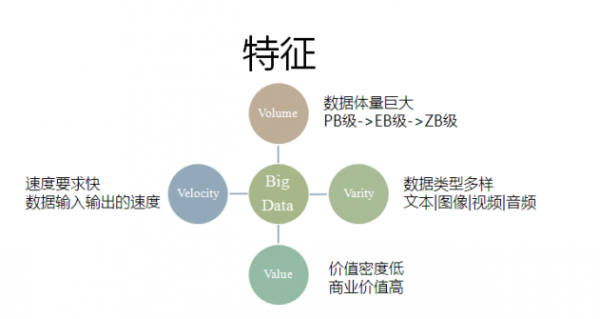
下图是大数据经典的4V特点。
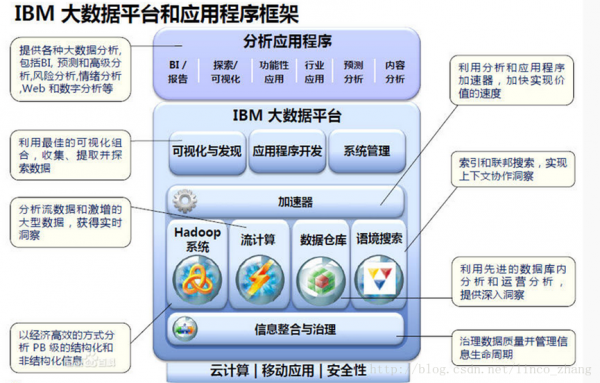
IBM大数据库框架及可视化技术,大数据经常使用:Hadoop、Spark,现在更多的是实时数据分析,包括淘宝、京东、附近美食等。
下图是大数据的1些利用。
说到大数据,就不能不提Hadoop,而说到Hadoop,又不能不提Map-Reduce。
MapReduce是1个软件框架由上千个商用机器组成的大集群上,并以1种可靠的,具有容错能力的方式并行地处理上TB级别的海量数据集。MapReduce的思想是“分而治之”。Mapper负责“分,Reducer负责对map阶段的结果进行汇总。
<2>.数据发掘(Data Mining)
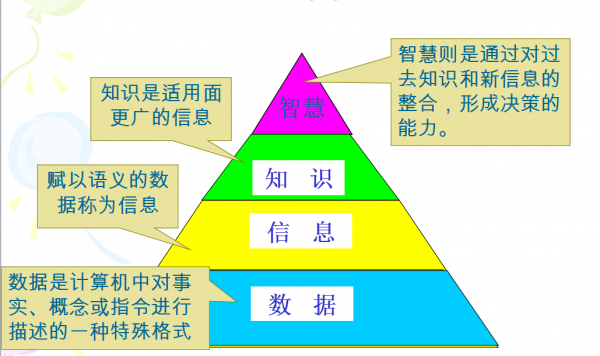
数据发掘(Data Mining):数据库、机器学习、人工智能、统计学的交叉学科。
数据发掘需要发现有价值的知识,同时最顶端都是具有智慧的去发现知识及有价值的信息。
由于这门课程主要是针对网页数据进行的大数据分析,需要Web Mining分类以下:
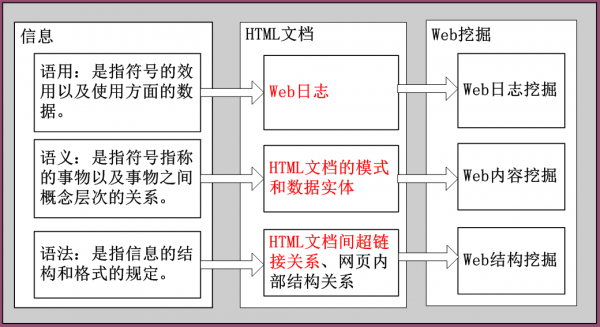
Web发掘主要分为3类:Web日志发掘、Web内容发掘、Web结构发掘。
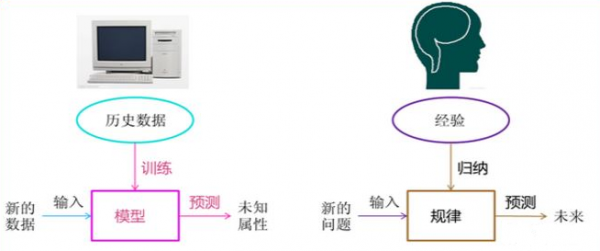
讲到机器学习和数据发掘相干的知识,我通常都会补充两幅图片,感觉真的很棒。很想象的表示了计算机灵能化与人类传统知识的类比。
推荐文章:机器学习:“1文读懂机器学习,大数据/自然语言处理/算法全有了”
2. 安装Python及基础知识
<1>.安装Python
在开始使用Python编程之前,需要介绍Python的安装进程。python解释器在Linux中可之内置使用安装,windows中需要去http://www.python.org官网downloads页面下载。具体步骤以下:
第1步:打开Web阅读器并访问http://www.python.org官网;
第2步:在官网首页点击Download链接,进入下载界面,选择Python软件的版本,作者选择下载python 2.7.8,点击“Download”链接。
Python下载地址:
第3步:选择文件下载地址,并下载文件。
第4步:双击下载的“python⑵.7.8.msi”软件,并对软件进行安装。
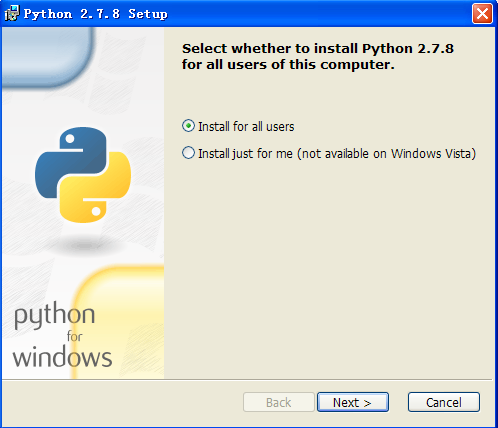
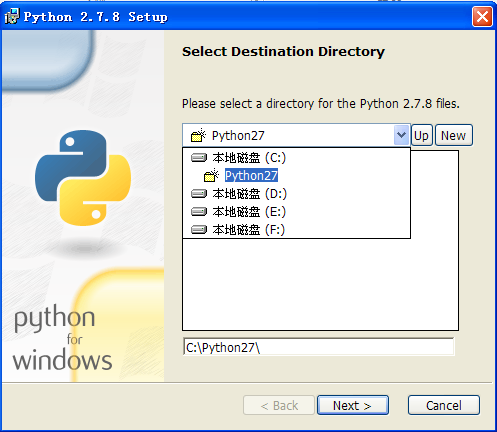
第5步:在Python安装向导当选择默许设置,点击“Next”,选择安装路径,这里设置为默许的安装路径“C:\Python27”,点击“Next”按钮,如图所示。
注意1:建议将Python安装在C盘下,通常路径为C:\Python27,不要存在中文路径。
在Python安装向导当选择默许设置,点击“Next”,选择安装路径,这里设置为默许的安装路径“C:\Python27”,点击“Next”按钮。
安装成功后,以下图所示:
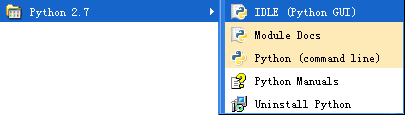
第6步:假定安装1切正常,点击“开始”,选中“程序”,找到安装成功的Python软件,如图所示:
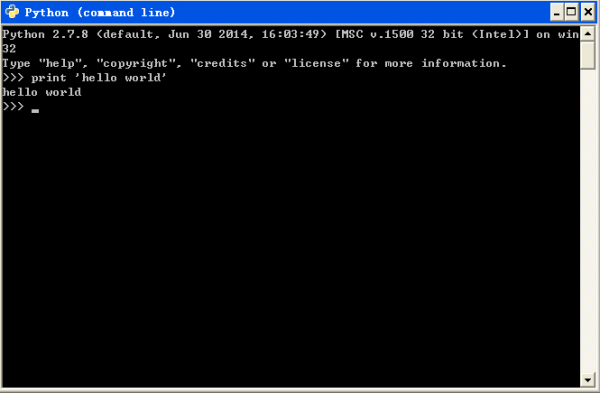
选中上图中第3个图标,即点击“Python (command line)命令行模式”,运行程序输入以下代码:
print 'hello world'
则python命令行模式的解释器会打印输出“hello world”字符串,以下图所示。
选中图中的第1个图片,点击“IDLE (Python GUI)”,即运行Python的集成开发环境(Python Integrated Development Environment,IDLE),运行结果以下图。
注意2:建议大家使用IDLE写脚本,完全的代码而不是通过命令行模式。
<2>.Python基础知识
这里简单入门介绍,主要介绍下条件语句、循环语句、函数等基础知识。
1、函数及运行
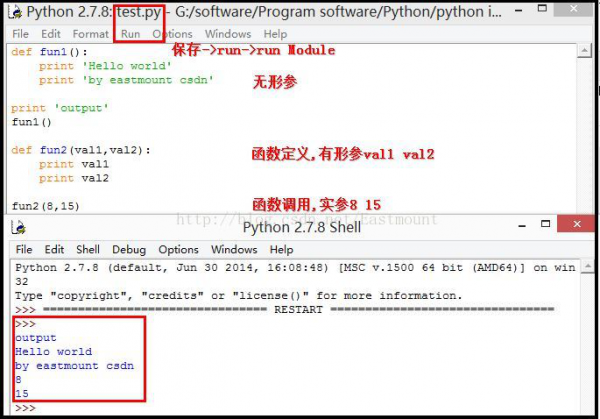
这里举个简单的例子。打开IDLE工具->点击栏"File"->New File新建文件->命名为test.py文件,在test文件里添加代码以下:
def fun1():
print 'Hello world'
print 'by eastmount csdn'
print 'output'
fun1()
def fun2(val1,val2):
print val1
print val2
fun2(8,15)
保存文件。并在test.py文件里点击Run->Run Module,输出结果以下图所示。
2、条件语句
包括单分支、双分支和多分支语句,if-elif-else。
(1).单分支语句
它的基本格式是:
if condition:
statement
statement
需要注意的是Ptthon中if条件语句条件无需圆括号(),条件后面需要添加冒号,它没有花括号{}而是使用TAB实现辨别。其中condition条件判断通常有布尔表达式(True|False 0-假|1-真 非0即真)、关系表达式(>=
<= == !=)和逻辑运算表达式(and or not)。
(2).双分支语句
它的基本格式是:
if condition:
statement
statement
else:
statement
statement
(3).多分支语句
if多分支由if-elif-else组成,其中elif相当于else if,同时它可使用多个if的嵌套。具体代码以下所示:
#双分支if-else
count = input("please input:")
print 'count=',count
if count>80:
print 'lager than 80'
else:
print 'lower than 80'
print 'End if-else'
#多分支if-elif-else
number = input("please input:")
print 'number=',number
if number>=90:
print 'A'
elif number>=80:
print 'B'
elif number>=70:
print 'C'
elif number>=60:
print 'D'
else:
print 'No pass'
print 'End if-elif-else'
#条件判断
sex = raw_input("plz input your sex:")
if sex=='male' or sex=='m' or sex=='man':
print 'Man'
else:
print 'Woman'
3、while循环语句
while循环语句的基本格式以下:
while condition:
statement
statement
else:
statement
statement
其中判断条件语句condition可以为布尔表达式、关系表达式和逻辑表达式,else可以省略(此处列出为与C语言等区分)。举个例子:
#循环while计数1+2+..+100
i = 1
s = 0
while i <= 100:
s = s+i
i = i+1
else:
print 'exit while'
print 'sum = ',s
'''
输出结果为:exit while
sum = 5050
'''
4、for循环
该循环语句的基础格式为:
for target in sequences:
statements
target表示变量名,sequences表示序列,常见类型有list(列表)、tuple(元组)、strings(字符串)和files(文件).
Python的for没有体现出循环的次数,不像C语言的for(i=0;i<10;i++)中i循环计数,Python的for指每次从序列sequences里面的数据项取值放到target里,取完即结束,取多少次循环多少次。其中in为成员资格运算符,检查1个值是不是在序列中。一样可使用break和continue跳出循环。
下面是文件循环遍历的进程:
#文件循环遍历3种对照
for n in open('for.py','r').read():
print n,
print 'End'
for n in open('for.py','r').readlines():
print n,
print 'End'
for n in open('for.py','r').readline():
print n,
print 'End'
5、课堂讲授代码
这是我课堂讲授的代码,仅供大家参考:
#coding=utf⑻
import os
import string
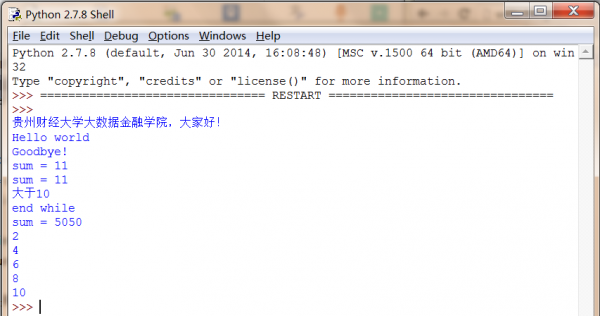
print '贵州财经大学大数据金融学院,大家好!'
def fun1():
print 'Hello world'
print 'Goodbye!'
#计算和
def fun2(n, m):
return n+m
#输出结果
fun1()
s = fun2(3,8)
print 'sum = ' + str(s)
print 'sum =', s
#判断语句 u表示unicode字符串
if(s>10):
print u'大于10'
else:
print u'小于等于10'
#循环语句
i = 1
s = 0
while i<=100:
s = s + i
i = i + 1
else:
print 'end while'
print 'sum =', s
'''
输出结果为:sum=5050
'''
#for循环
num = [2, 4, 6, 8, 10]
for x in num:
print x
输出结果以下图所示:
3. 安装PIP及第3方包
接下来需要详解介绍爬虫相干的知识了,这里主要触及到下面几个知识:

爬虫主要使用Python(字符串|urllib)+Selenium+PhantomJS+BeautifulSoup。
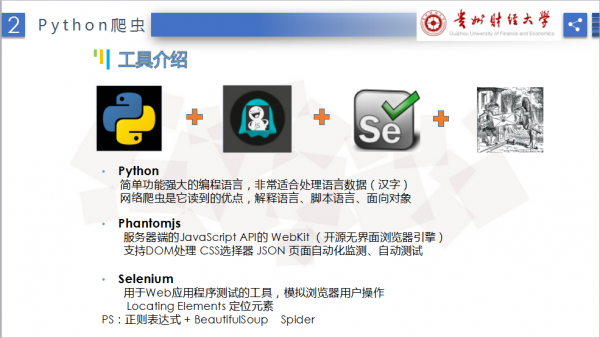
PIP
在介绍介绍它们之前,需要安装PIP软件。正如xifeijian大神所说:“作为Python爱好者,如果不知道easy_install或pip中的任何1个的话,那末......”。
easy_insall的作用和perl中的cpan,ruby中的gem类似,都提供了在线1键安装模块的傻瓜方便方式,而pip是easy_install的改进版,提供更好的提示信息,删除package等功能。老版本的python中只有easy_install,没有pip。常见的具体用法以下:
easy_install的用法:
1) 安装1个包
$ easy_install <package_name>
$ easy_install "<package_name>==<version>"
2) 升级1个包
$ easy_install -U "<package_name>>=<version>"
pip的用法
1) 安装1个包
$ pip install <package_name>
$ pip install <package_name>==<version>
2) 升级1个包 (如果不提供version号,升级到最新版本)
$ pip install --upgrade <package_name>>=<version>
3)删除1个包
$ pip uninstall <package_name>
第1步:下载PIP软件
可以在官网http://pypi.python.org/pypi/pip#downloads下载,同时cd切换到PIP目录,在通过python setup.py
install安装。而我采取的是下载pip-Win_1.7.exe进行安装,下载地址以下:
这里作者提供几种方法供大家下载:
http://download.csdn.net/detail/eastmount/9598651
第2步:安装PIP软件
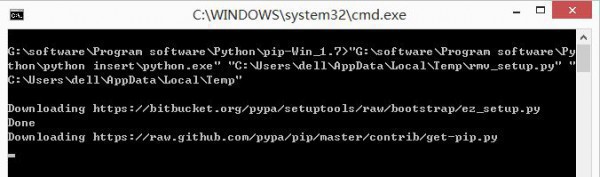
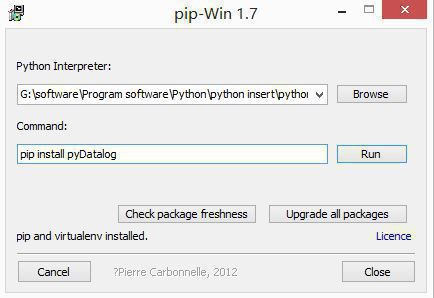
当提示"pip and virtualenv installed"表示安装成功,那怎样测试PIP安装成功呢?
第3步:配置环境变量
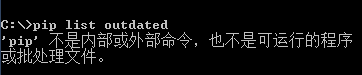
此时在cmd中输入pip指令会提示毛病“不是内部或外部命令”。
注意:两种解决方法,1种是通过cd ..去到Srcipts环境进行安装,pip install...
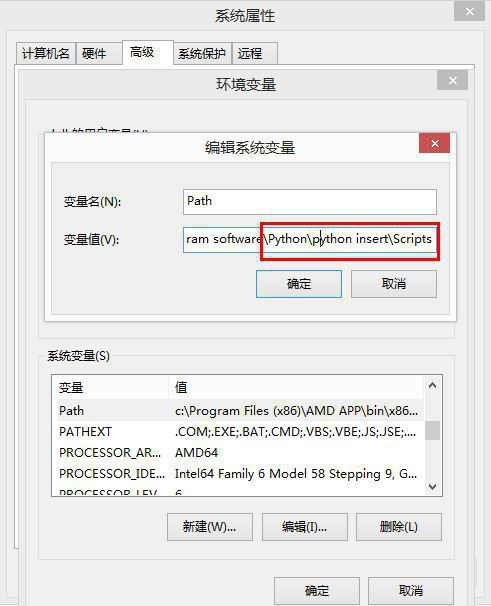
方法2:另外一种配置Path路径。
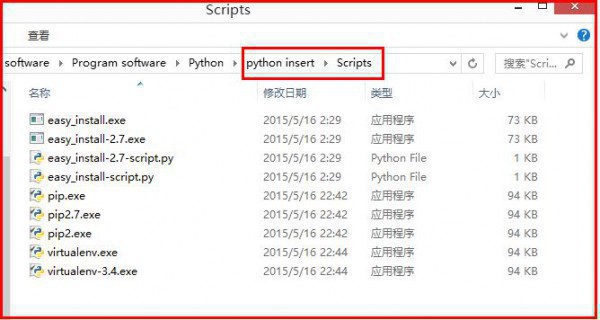
需要添加path环境变量。PIP安装完成后,会在Python安装目录下添加python\Scripts目录,即在python安装目录的Scripts目录下,将此目录加入环境变量中便可!进程以下:
第4步:使用PIP命令
下面在CMD中使用PIP命令,“pip list outdate”罗列Python安装库的版本信息。
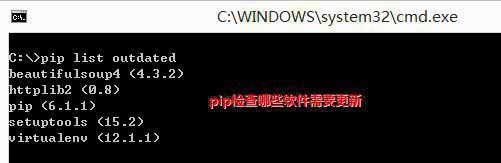
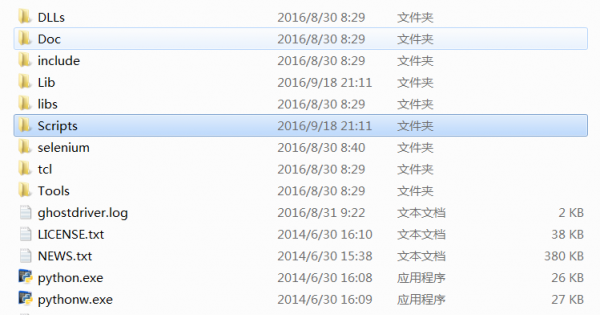
注意:安装成功后,会在Python环境中增加Scripts文件夹,包括easy_install和pip。
PIP安装进程中可能出现各种问题,1种解决方法是去到python路径,通过python set_up.py install安装;另外一种是配置Path环境比例。
课堂重点知识:
第1节课主要想让大家体会下Python网络爬虫的进程及示例。需要安装的第3方库主要包括3个:
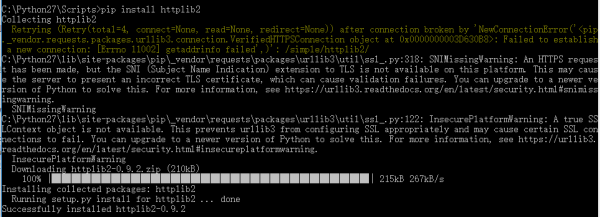
pip install httplib2
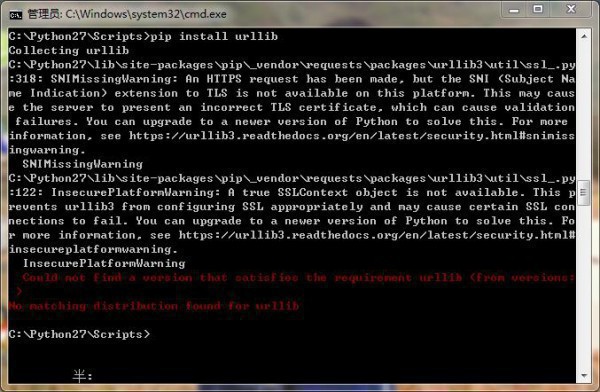
pip install urllib
pip install selenium
在安装进程中,如果pip install urllib报错,是由于httplib2包括了,可直接用。
4. Urllib下载网页及图片
在使用pip install urllib或pip install urllib2后,下面这段代码是下载网页。
#coding=utf⑻
import os
import urllib
import httplib2
import webbrowser as web
#爬取在线网站
url = "http://www.baidu.com/"
content = urllib.urlopen(url).read()
open("baidu.html","w").write(content)
#阅读求打开网站
web.open_new_tab("baidu.html")
首先我们调用的是urllib2库里面的urlopen方法,传入1个URL,这个网址是百度首页,协议是HTTP协议,固然你也能够把HTTP换做FTP、FILE、HTTPS 等等,只是代表了1种访问控制协议,urlopen1般接受3个参数,它的参数以下:
urlopen(url, data, timeout)
第1个参数url即为URL,第2个参数data是访问URL时要传送的数据,第3个timeout是设置超时时间。
第23个参数是可以不传送的,data默许为空None,timeout默许为 socket._GLOBAL_DEFAULT_TIMEOUT。
第1个参数URL是必须要传送的,在这个例子里面我们传送了百度的URL,履行urlopen方法以后,返回1个response对象,返回信息便保存在这里面。
response = urllib2.urlopen("http://www.baidu.com")
print response.read()
response对象有1个read方法,可以返回获得到的网页内容。
获得的网页本地保存为"baidu.html",通过阅读器打开以下图所示:
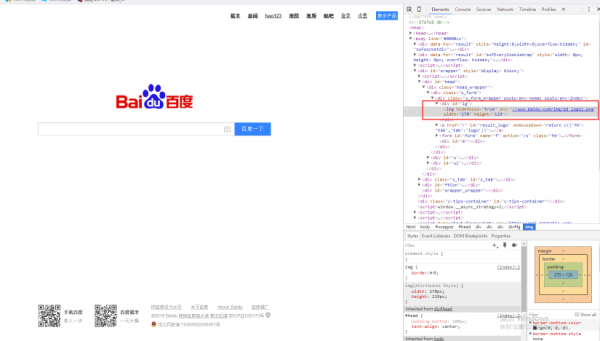
然后是需要下载图片,这里需要学会找到图片的URL,以下图百度的LOGO,可以通过阅读器右键"审查元素"或"检查"来进行定位。
定位URL后,再通过函数urlretrieve()进行下载。
#coding=utf⑻
import os
import urllib
import httplib2
import webbrowser as web
#爬取在线网站
url = "http://www.baidu.com/"
content = urllib.urlopen(url).read()
open("baidu.html","w").write(content)
#阅读求打开网站
web.open_new_tab("baidu.html")
#下载图片 审查元素
pic_url = "https://www.baidu.com/img/bd_logo1.png"
pic_name = os.path.basename(pic_url) #删除路径获得图片名字
urllib.urlretrieve(pic_url, pic_name)
#本地文件
content = urllib.urlopen("first.html").read()
print content
#下载图片 审查元素
pic_url = "imgs/bga1.jpg"
pic_name = os.path.basename(pic_url) #删除路径获得图片名字
urllib.urlretrieve(pic_url, pic_name)
重点知识:
urllib.urlopen(url[, data[, proxies]]) :创建1个表示远程url的类文件对象,然后像本地文件1样操作这个类文件对象来获得远程数据。
urlretrieve方法直接将远程数据下载到本地。
如果需要显示进度条,则使用下面这段代码:
import urllib
def callbackfunc(blocknum, blocksize, totalsize):
'''回调函数
@blocknum: 已下载的数据块
@blocksize: 数据块的大小
@totalsize: 远程文件的大小
'''
percent = 100.0 * blocknum * blocksize / totalsize
if percent > 100:
percent = 100
print "%.2f%%"% percent
url = 'http://www.sina.com.cn'
local = 'd:\\sina.html'
urllib.urlretrieve(url, local, callbackfunc)
5. HTML网页基础知识及审查元素
HTML DOM是HTML Document Object Model(文档对象模型)的缩写,HTML DOM则是专门适用于HTML/XHTML的文档对象模型。熟习软件开发的人员可以将HTML DOM理解为网页的API。它将网页中的各个元素都看做1个个对象,从而使网页中的元素也能够被计算机语言获得或编辑。
DOM是以层次结构组织的节点或信息片断的集合。这个层次结构允许开发人员在树中导航寻觅特定信息。分析该结构通常需要加载全部文档和构造层次结构,然后才能做任何工作。由于它是基于信息层次的,因此 DOM 被认为是基于树或基于对象的。
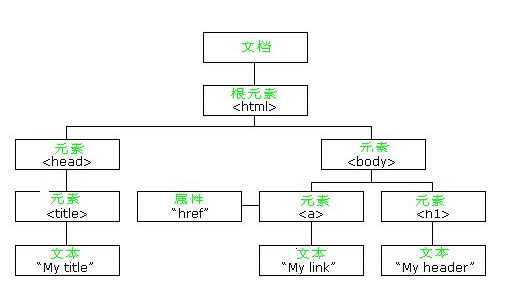
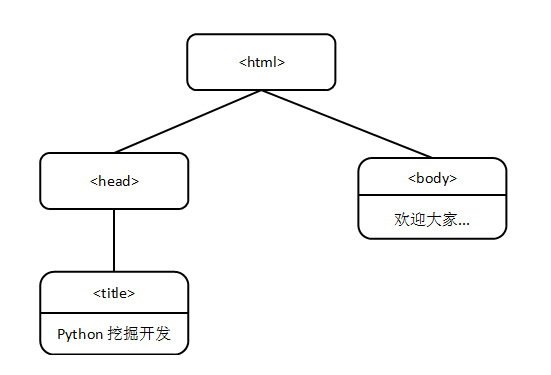
HTML DOM 定义了访问和操作HTML文档的标准方法。 HTML DOM 把 HTML 文档显现为带有元素、属性和文本的树结构(节点树)。它们都是1个节点(Node),就像公司的组织结构图1样。 我们现在从另外一个角度来审视源代码,first.html的源码以下:
<html>
<head>
<title>Python发掘开发</title>
</head>
<body>
欢迎大家学习《基于Python的Web大数据爬取实战指南》! <br>
</body>
</html>
这个例子的第1个元素就是<html>元素,在这个元素的起始标签和终止标签之间,又有几个标签分别起始和闭合,包括<head>、<title>和<body>。<head>和<body>标签是直接被<html>元素包括的,而<title>标签则包括在<head>标签内。要描写1个HTML网页的这类多层结构,用树来进行类比是最好的方式。树形结构以下图所示:
重点:
在网络爬虫中,通常需要结合阅读器来定位元素,阅读器右键通常包括两个重要的功能:查看源代码和审查或检查元素。
通过审查元素,可以定位到需要爬取图片或网页的HTML源文件,通常是table或div的布局,这些HTML标签通常是成对出现的,如<html></html>、<div></div>等;同时会包括1些属性id、name、class来指定该标签。如:
<div id="content" name="n1" class="cc">....</div>
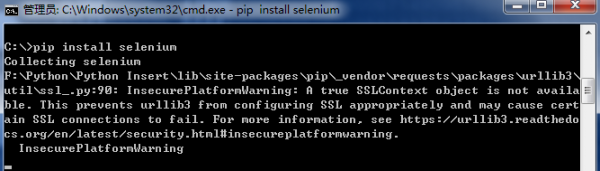
6. 安装Selenium及网页简单爬取
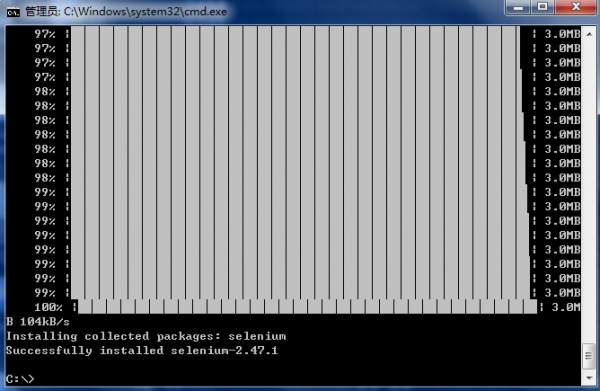
Selenium用于Web利用程序测试的工具,摹拟阅读器用户操作,通过Locating Elements 定位元素。安装进程以下图所示,通过pip install selenium安装。
注意:需要cd去到Scripts目录进行安装。
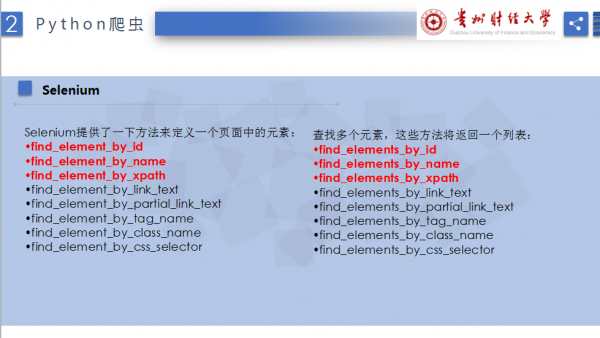
selenium结合阅读器定位的基本函数包括:
推荐文章,同时下节课会详细介绍。
[python爬虫] Selenium常见元素定位方法和操作的学习介绍
第1个基于Selenium爬虫的代码,通过调用Firefox阅读器:
#coding=utf⑻
import os
import urllib
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
#Open PhantomJS
#driver = webdriver.PhantomJS(executable_path="phantomjs⑴.9.1-windows\phantomjs.exe")
driver = webdriver.Firefox()
#访问url
driver.get("https://www.baidu.com/")
print u'URL:'
print driver.current_url
#当前链接: https://www.baidu.com/
print u'标题:'
print driver.title
#标题: 百度1下, 你就知道
#print driver.page_source
#源代码
#定位元素,注意u1(数字1)和ul(字母L)区分
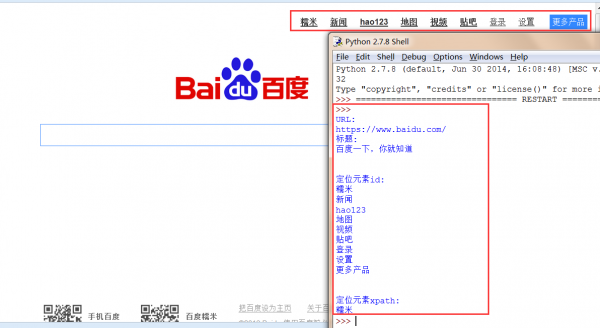
print u'\n\n定位元素id:'
info1 = driver.find_element_by_id("u1").text
print info1
#定位元素
print u'\n\n定位元素xpath:'
info3 = driver.find_element_by_xpath("//div[@id='u1']/a")
print info3.text
输出以下图所示:
希望这篇文章对你有所帮助,主要是介绍基本的安装进程及体会下Python爬虫知识,后面会陆续详细介绍相干内容。非常想上好这门课,由于是我的专业方向,另外学生们真的好棒,好认真,用手机录相、问问题、配环境等等,只要有用心的学生,我定不负你!同时,自己授课思路有些乱,还需加强,但还是挺享受的,毕竟9800,哈哈哈!
(By:Eastmount 2016-09⑴9 晚上10点 http://blog.csdn.net/eastmount/ )
生活不易,码农辛苦
如果您觉得本网站对您的学习有所帮助,可以手机扫描二维码进行捐赠