
上1篇我们介绍了代表RDD组成的(Dependency、Partition、Partitioner)之1的Partition,这篇接着介绍Dependency。Partition记录的是数据split的逻辑,Dependency记录的是transformation操作进程中Partition的演变,即这个Partition从哪来到哪去的进程。
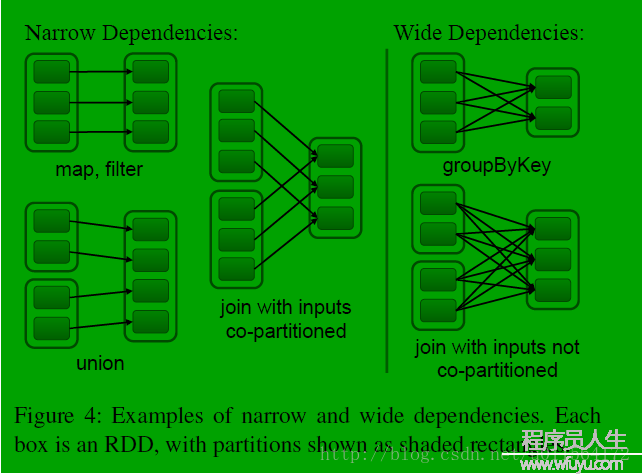
我的另外一篇博客Spark RDD中介绍了RDD的组成,及Dependency的分类和缘由,这里不再累述,先看下Dependency的定义:

Dependency是抽象类,有1个抽象方法rdd,Dependency其实就是父RDD的包装,其主要子类实现有两大类:


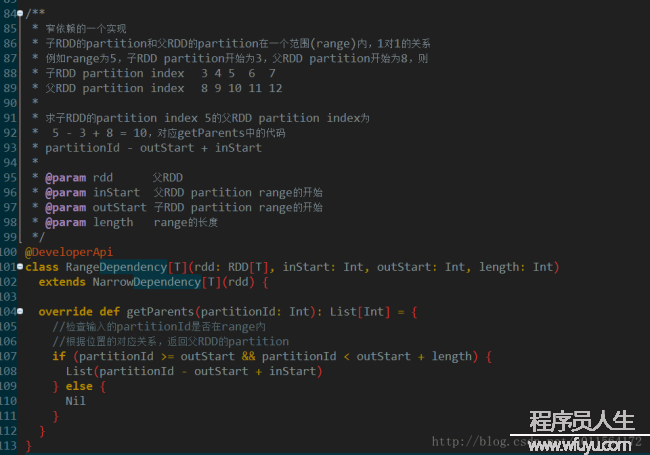 RangeDependency表示子RDD和父RDD的Partition之间的关系是1个区间内的1对1对应关系,第1幅图中所示Narrow Dependency下面的union就是RangeDependency
RangeDependency表示子RDD和父RDD的Partition之间的关系是1个区间内的1对1对应关系,第1幅图中所示Narrow Dependency下面的union就是RangeDependency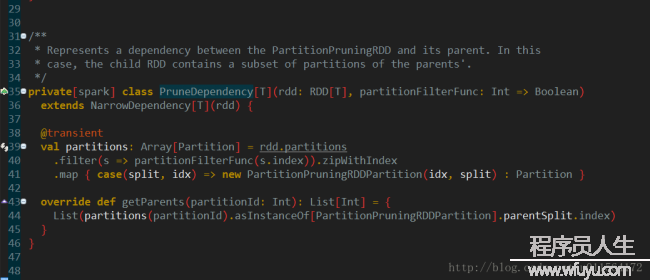 子RDD的Partition来自父RDD的多个Partition,filterByRange方法时会使用,不做详细讨论
子RDD的Partition来自父RDD的多个Partition,filterByRange方法时会使用,不做详细讨论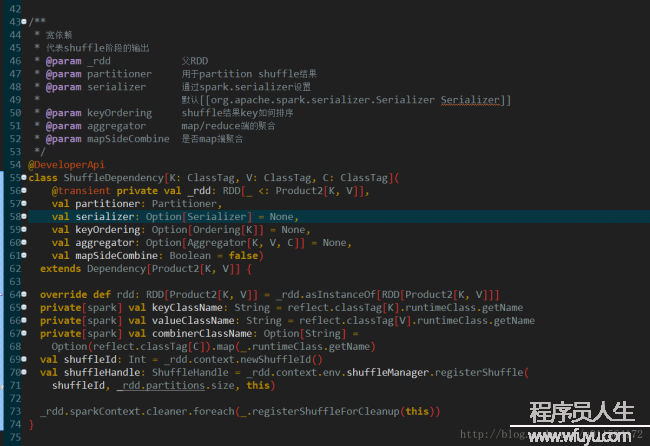 ShuffleDependency的定义相对复杂1些,由于shuffle设计到网络传输,所以要有序列化serializer,为了减少网络传输,可以加map端聚合,通过mapSideCombine和aggregator控制,还有key排序相干的keyOrdering,和重输出的数据如何分区的partitioner,其他信息包括k,v和combiner的class信息和shuffleId。shuffle是个相对复杂且开消大的进程,Partition之间的关系在shuffle处戛但是止,因此shuffle是划分stage的根据。
ShuffleDependency的定义相对复杂1些,由于shuffle设计到网络传输,所以要有序列化serializer,为了减少网络传输,可以加map端聚合,通过mapSideCombine和aggregator控制,还有key排序相干的keyOrdering,和重输出的数据如何分区的partitioner,其他信息包括k,v和combiner的class信息和shuffleId。shuffle是个相对复杂且开消大的进程,Partition之间的关系在shuffle处戛但是止,因此shuffle是划分stage的根据。Dependency分为两大类,宽依赖和窄依赖,窄依赖有两个主要实现。
以Wordcount为例
val wordcount = sc.parallelize(List("a c", "a b"))
wordcount.flatMap(_.split(" ")).map((_, 1)).reduceByKey(_ + _).collect()
通过web UI查看DAG,以下:
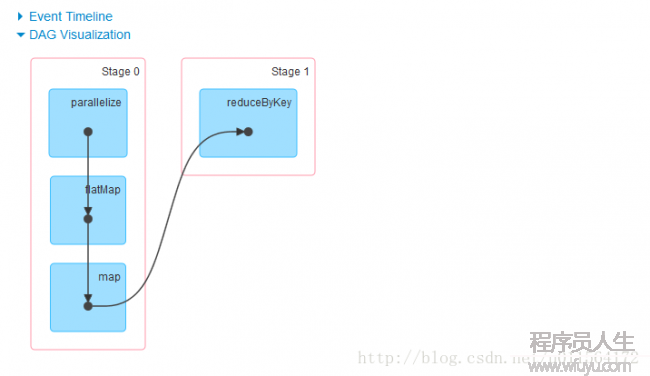
可以看出,其根据shuffle的位置划分为两个stage,stage0和stage1
调用toDebugString查看各RDD之间关系

最后,总结出Wordcount中RDD及其对应的Dependency以下,其中方形代表RDD,圆角矩形代表Partition(3个圆角矩形是为了作图方便,不代表其具体有3个Partition),文本框内第1行动代码片断,第2行是对应的RDD,第3行动RDD的Dependency类型
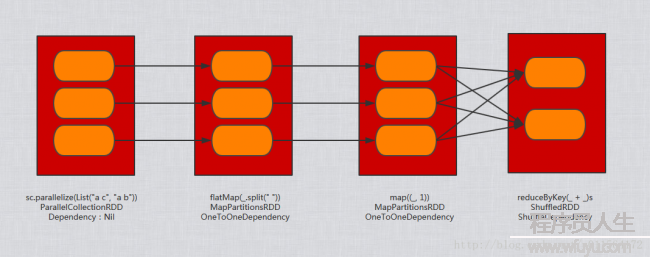
Dependency是RDD的重要组成,分为宽依赖和窄依赖两大类,实质就是其父RDD的包装,由Dependency组成的关系构成了lineage的物理结构,也是DAG的物理结构,宽依赖(即shuffle操作)也是stage划分的根据,窄依赖可以履行流水线(pipeline)操作,效力高。

程序员人生,我编程,我富裕,记住wfuyu网,php教程,php学习,php手册,CMS模版制作
声明:本站大部分内容是作者原创,少部分收集于互联网供大家一起学习,原版权很多不明,如有侵权请联系本站,谢谢!
粤ICP备14040726号-1 2015-2020 程序员人生 版权所有


